

Transformer
论文:Attention is all you need
Transformer的基础是Self-Attention,集齐了上面一节Self-Attention中的所有东西之后,可以召唤Transformer出场了
Transformer是真正双向的,而不像Bi-LSTM那种“假双向”
结构
add是把上一个multi-head attention的[输入]与[输出]加起来,采用了ResNet一样的思想,可以防止像Transformer这种深度结构出现梯度弥散问题
norm指的是layer normlization与batch normalization不同,layer normalization一般搭配RNN/Transformer
BN是一个batch里的不同向量的同一维度做标准化
LN是一个batch里的同一向量的所有维度做标准化
Feed forward层【-】
Masked Multi-head Attention:在Decoder中,我们输入masked就是输出层在计算第$j$个词与其他词的attention时,只考虑$j$前面的词,因为$j$后面的词我们不知道是什么,所以我们要把后面的位置给mask掉
注意Decoder的Multi-head Attention的输入,$K,V$来源于Encoder中最顶层Transformer中的$K,V$
此时这个$K,V$已经编码了input中的信息,以$key-value$形式,而$query$来自于decoder的上一个输入(从起始符开始),就相当于是一个”查找最可能的输出“的过程。
这种attention叫encoder-decoder attention
注意Transformer是怎么训练的【-】
每个Encoder的输入首先会通过一个self-attention层,通过self-attention层帮助Endcoder在编码单词的过程中查看输入序列中的其他单词。
图中灰色部分重复很多次
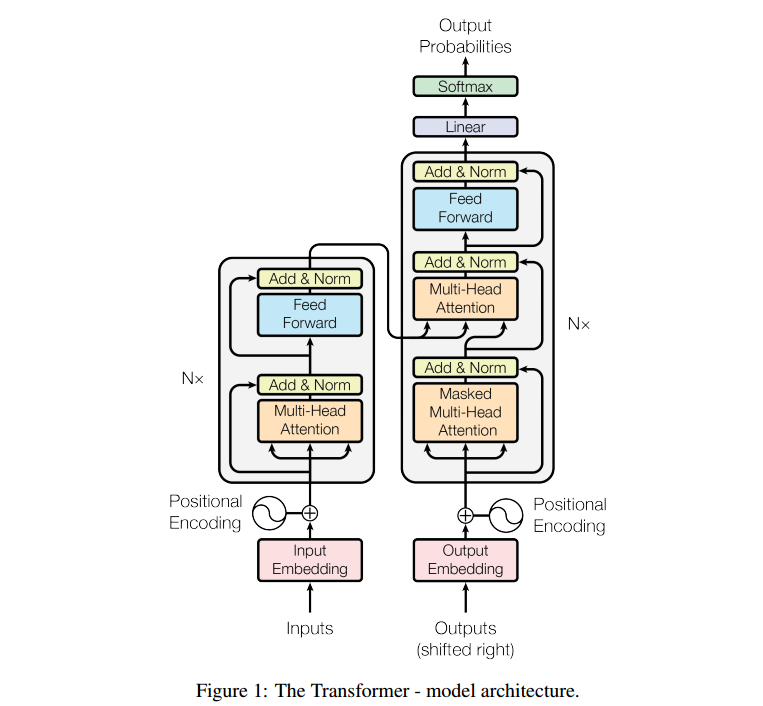
不突出细节的结构图:
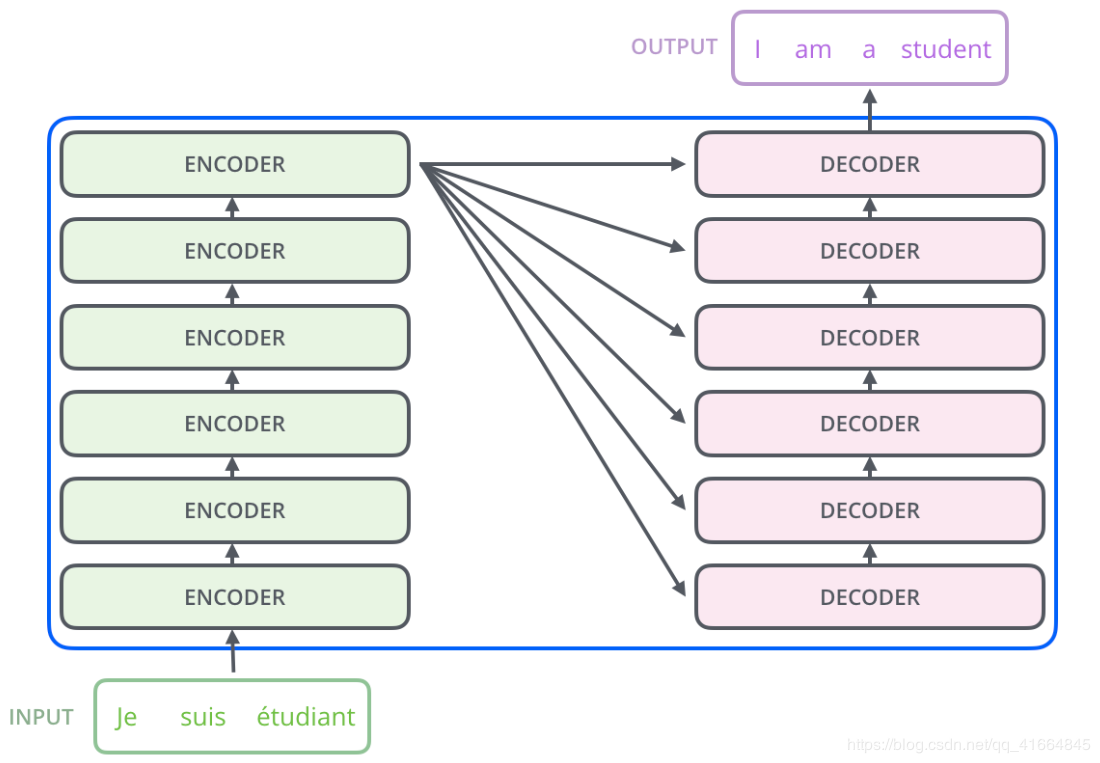
Transformer [预测]过程动图:

Transformer-XL
API
pytorch中包含对Transformer的支持,nn.Transformer模块,也可以单独使用nn.TransformerEncoder和nn.TransformerEncoderLayer,nn.TransformerDecoder和nn.TransformerDecoderLayer
torch.nn.Transformer(d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=2048, dropout=0.1, activation='relu', custom_encoder=None, custom_decoder=None) #默认参数具体代码实现看源码
BERT
BERT 的创新点在于使用了 Transformer 用于语言模型,Transformer是真正双向的,而不像Bi-LSTM那种“假双向”
论文中介绍了一种新技术叫做 Masked LM(MLM),在这个技术出现之前是无法进行双向语言模型训练的
预训练中Word2vec,ELMO,GPT与BERT对比
堆叠Transformer(有Multihead Attention),像CNN一样层层提取特征,逐层(Encoder)提取高级语义
而word2vec只有一层隐藏层
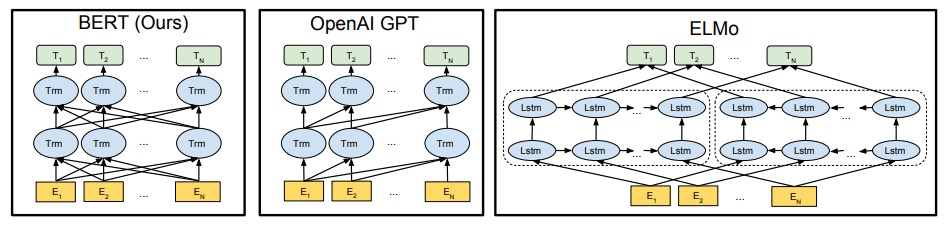
左为BERT
可以看出:BERT解决了ELMo无法双向问题,替换了ELMo中的LSTM为更优越的Transformer
GPT是单向Transformer
预训练
上面的网络结构是Google预训练的
Pre-training Task 1#: Masked LM
大部分替换成MASK,少部分替换成其它词,少部分不替换
看能否预测出原词
Pre-training Task 2#: Next Sentence Prediction
因为涉及到QA和NLI之类的任务,增加了第二个预训练任务,目的是让模型理解两个句子之间的联系。训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,模型预测B是不是A的下一句。预训练的时候可以达到97-98%的准确度。
Fine-Tune
略
比较 优缺点
word2vec: nlp中最早的预训练模型,缺点是无法解决一词多义问题.
ELMO:
优点: 根据上下文动态调整word embedding,因为可以解决一词多义问题;
缺点:1、使用LSTM特征抽取方式而不是transformer,2、使用向量拼接方式融合上下文特征融合能力较弱。
GPT:.
优点:使用transformer提取特征
缺点:使用单项的语言模型,即单向transformer.
BERT: 优点:使用双向语言模型,即使用双向transformer;使用预测目标词和下一句这中多任务学习方式进行训练。
无论RNN LSTM word2vec Transformer BERT,都是在训练词向量,不过RNN LSTM是非预训练的
训练好词向量,嵌入之后,根据具体的任务进行处理
中文改进BERT
略


