

docker的使用
docker三大概念:镜像(Image)、容器(Container)和仓库(Repository)
Registry是注册机构,可以管理多个仓库,参考:docker镜像的commit与push
dockerfile是制作镜像的脚本,其描述了镜像如何制作和镜像的参数(重要),详细见:DockerFile与镜像(Image)仓库
镜像是冷的文件,镜像可以从仓库里拉取,也可以推送到仓库;可以由dockerfile创建,也可以由容器创建
启动镜像就会为其创建一个容器,容器有运行、暂停、停止三个状态
docker端口和宿主端口要对应,可以指定多个端口映射;目录也可以指定与宿主的映射
docker命令大全:
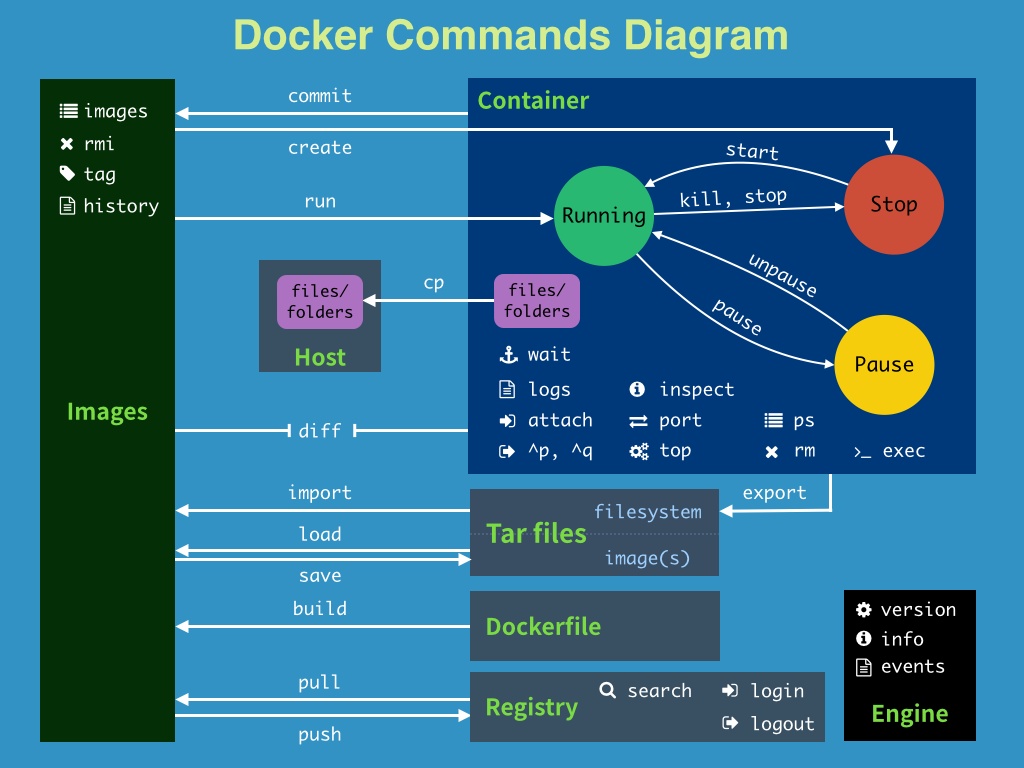
详细说明:
P.S. docker镜像的命名一般是<name:tag>,不写tag则默认tag是latest
# ====从远程仓库拉取镜像到本地====
docker pull <name>
# 如何设置默认仓库见https://www.cnblogs.com/silva/p/11505925.html
# 可以创建自己的仓库服务,以阿里云为例,见 阿里云-容器镜像服务 说明
# 可以指定从哪个registry的哪个仓库拉取,比如registry是myregistry.local:1234,仓库是aisaka-test,想要拉取test-image:
docker pull myregistry.local:1234/aisaka-test/test-image
# 在仓库搜索镜像
docker search
# ====推送容器镜像到远程镜像仓库====
docker push <name>
# 同pull一样也可以push到指定仓库
docker push myregistry.local:1234/aisaka-test/test-image
# ====查看本地镜像====
docker images
# 删除本地镜像
docker rmi <name>
# ====从容器生成镜像====
docker commit -a "aisaka" -m "test" nextcloud nextcloud:v1
# -a :提交的镜像作者;
# -c :使用Dockerfile指令来创建镜像;
# -m :提交时的说明文字;
# -p :在commit时,将容器暂停。
# nextcloud:v1是我给生成镜像取的名字,:后面跟着的是TAG,用于标识版本
# ====用dockerfile生成镜像====
docker build
# 见https://www.runoob.com/docker/docker-build-command.html
# ====镜像创建容器====
docker create <name>
# 与run的区别在于,create创建的容器是stop状态,而run是running状态
# ====【运行容器镜像】====
docker run -d -p 3306:3306 -v /mnt/sde/mysql:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=WZS134125 --name mysql mysql
# -d 后台守护进程方式运行(启动后进入后台)
# -p 端口映射,宿主端口:容器端口【重要】
# -v 目录挂载,宿主目录:容器目录【重要】
# -e 设置变量
# --name 设置容器名称【别忘了】
# 最后一个 即为要运行的镜像名
# 【多端口,多目录映射】-p和-v参数都可以有多个,即可以指定多个端口和目录映射
# ====容器的暂停、终止====
# 容器终止
docker stop <name>
# 启动已终止运行的容器
docker start <name>
# 清理掉所有处于终止状态的容器
docker container prune
# 暂停容器
docker pause <name>
# 继续已暂停的容器
docker unpause <name>
# 重启容器
docker restart <name>
# ====删除容器====
docker rm -f <name>
# 删除容器不是删除镜像
# -f可以删除未终止的容器;安全的操作是先终止再删除,-f可以省事
docker rm -v
# -v 会同时删除该容器挂载的volume(且没有其它容器连接到该Volume,否则不会删除)
# ====进入容器====
docker exec -it mysql /bin/bash
#-it 分配一个虚拟终端,进入该容器命令行界面
# /bin/bash 放在镜像名后的是命令,这里我们希望使用/bin/bash。
# ====不进入容器执行语句====
docker exec <container name> <command>
#也很常用,进入容器执行很麻烦
# ====容器与宿主复制====
docker cp <宿主文件地址> <name>:<容器文件地址>
# ====查看容器状态====
docker ps
# ====镜像打包相关====
# 将镜像打包成tar(打包就是压缩,格式为tar)
docker save -o myImages.tar myImages
#-o 指定打包后的名字
# 导入tar打包的镜像(导入到本地镜像仓库)
docker load < myImages.tar
# 生成容器快照:容器直接打包成tar镜像(相当于commit+save)
docker export <name> > myDockerImage.tar
# 导入容器快照:将打包的tar镜像直接生成容器(相当于load+run)
docker import
# 使用见:https://www.simapple.com/327.html
# 给镜像打tag
docker tag
#查看docker信息
docker inspect <docker name>pull、push、run,commit,images,ps,rmi,rm,cp,build等都是很常用的命令
dockerfile是个文本文件,记录了一个镜像的制作过程。执行docker build即可制作镜像,详见dockerfile
而docker commit是将容器直接制作成镜像
dockerfile主要目的是将镜像制作细节展示出来,比commit直接给你个黑盒更易用,更容易看懂这个镜像到底是干嘛的
docker-compose用于容器的编排
多个docker之间要相互合作,比如nginx、mysql、nextcloud每个组件都在一个容器里,那我就需要docker-compose。将项目需要哪些镜像,每个镜像怎么配置,要挂载哪些volume等等信息都写在docker-compose.yml里来实现容器的协同工作
dockerfile记录了单个镜像的构建过程,而docker-compose.yml记录了一个项目(多个镜像)的构建过程
容器快照import和打包load的区别
容器快照将会丢弃所有的历史记录和元数据信息,而镜像存储文件将保存完整记录,体积也会更大。
是将宿主端口映射到容器端口,将宿主目录/volume挂载到容器目录(容器目录是挂载点,宿主目录/容器是被挂载卷),所以run的-v和-p参数都是宿主在前,容器在后
docker数据持久化
bind mount
在使用run语句进行目录挂载的时候,docker run的时候指定-v 参数
bind mount方式:-v 目录挂载,宿主目录:容器目录
bind mount方式简单明了,就是直接将宿主目录挂载到指定容器目录上
但问题在于这样就在不同的宿主机系统时不可移植,且必须指定全路径,不能在dockerfile里写
volume
volume方式(建议):-v 目录挂载,volume名:容器目录
先在宿主新建一个volume,然后再将volume挂载到指定容器内的挂载点上。容器目录是不会变的,迁移的时候新建volume直接指定名字即可,所以也不需要改变。
volume是被docker管理的,docker下所有的volume都在host机器上的指定目录下/var/lib/docker/volumes
最常用的就是volume方式
# 新建一个volume
docker volume create my-volume
# 挂载
docker run -v my-volume:/var/lib/mysql mysql
# (省略掉了其它参数)如果不指定volume的话,也会挂载到该目录,不过名字是随机生成的一串id
docker run -v /var/lib/mysql mysql
# 未指定volume,自动生成了使用dockerfile的话,直接写VOLUME项的挂载点即可
VOLUME /var/lib/mysql但是,通过 dockerfile的VOLUME 指令创建的挂载点,是自动生成的默认容器名字(和前面一样)!
docker的volume也有一套管理工具
docker volume create <volume name>
docker volume inspect <volume name> #查看指定容器详细信息
docker volume ls
docker volume rm
docker volume prune #删掉本地所有未使用的容器
# 删除容器的时候同时删除挂载的volume(前提是没有其它容器连接到该Volume,否则不会删除)
docker rm -v关于volume的迁移:Docker数据卷Volume的备份,迁移,恢复
docker-compose也可以设置volume,且可以指定volume挂载目录!结合后面一节docker-compose看
建议首选在docker-compose中配置volume(最方便、明了)(等其它参数),而不是在dockerfile中
version: '2' # 表示该 Docker-Compose 文件使用的是 Version 2 file
services:
docker-demo: # 指定服务名称
build: . # 指定 Dockerfile 所在路径
ports: # 指定端口映射
- "9000:8761"
volumes:
- <宿主目录volumes地址>:<容器挂载目录> #使用具体路径直接挂载到本地
- <volumes名>:<容器挂载目录> #直接使用volumes名,但不能设置volumes目录,自动挂载在/var/lib/docker/volumes目录
生命周期
容器中未被宿主目录挂载的目录和里面的数据,将被储存在容器里,随容器删除而删除
所以要想将数据和容器隔离,必须用前面的方式做数据持久化,只有被挂载的数据会被持久化
P.S.1 容器目录不可以为相对路径
P.S.2 显然,两种方法都可以做到容器之间共享数据(宿主目录or volume可挂载到多个容器的挂载点上)
dockerfile
常用命令:FROM(基础镜像)、MAINTAINER(作者信息)、RUN(执行命令)、EXPOSE(容器内打开的端口,运行镜像的时候还需要指定这些端口到宿主的映射)、CMD(默认命令)、ENTRYPOINT、ADD、COPY(将文件或目录从宿主复制到Dockerfile构建的镜像中)、VOLUME(向容器添加卷,可以提供共享存储等功能)、WORKDIR(容器内部设置工作目录)、ENV(设置环境变量,运行容器的时候可以指定env参数)、USER(什么用户运行镜像)、ONBUILD(镜像创建触发器,当一个镜像被用作其他镜像的基础镜像时,这个触发器会被执行)
通过ADD、COPY、RUN就可以将自己写的代码如jar包war包放进去跑,或者数据库表文件什么的放进去,总之有这些参数就可以生成自己想要的镜像了
Dockerfile的构建过程:
- docker会从Dockerfile文件头FROM指定的基础镜像运行一个容器
- 然后执行一条指令,对容器修改
- 接着执行类似docker commit的操作,创建新的镜像层
- 在基于刚创建的镜像运行一个新的容器
- 执行Dockerfile下一条指令,直到所有指令执行完毕
docker会删除中间层创建的容器,但不会删除中间层镜像,所以可以使用docker run运行一个中间层容器,从而查看每一步构建后的镜像状态,这样就可以进行调试。
P.S. docker CMD 和 ENTRYPOINT 区别
docker原理
docker是一种容器技术。
容器运行在OS内核之上
Docker使用Google公司推出的Go语言进行开发实现,基于Linux内核的cgroup,namespace,以及AUFS类的UnionFS等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术。
操作系统(OS)是管理计算机硬件、软件资源,并为计算机程序提供通用服务的系统软件。而管理硬件、软件资源,都是由内核实现的。docker镜像是不含内核的,容器与宿主机共享内核。docker镜像只包含一部分提供通用服务的用户态(userland),如各种lib、系统应用,还有一部分服务由内核提供。
操作系统分为内核和用户空间。对于Linux而言,内核启动后,会挂载root文件系统为其提供用户空间支持。而Docker镜像(Image),就相当于是一个root文件系统。现在引入容器之后:我们开机的时候,linux内核会先启动,然后挂载root文件系统作为用户空间;而Docker镜像就相当于是一个root文件系统,每开一个就有了一个独立的用户空间。
容器是运行在操作系统内核之上的,容器对进程进行了封装隔离,属于不同容器之间是进程级隔离,不同容器之间OS内核是共用的。
VM和容器
而VM是OS级别的隔离,不同的VM有自己的OS内核,只有硬件共用,软件完全隔离开。
不同的docker进程不能映射到同一个端口,而VM可以(端口指的是我们访问主机(OS内核)上的某一进程的标识号,而docker是进程级隔离,并没有达到OS级隔离,所以不同容器不能映射同一端口;而VM是OS级隔离的,所以可以映射到同一端口)因为docker的隔离程度没有VM高
容器相比VM非常轻量,快。
容器和镜像
镜像是静态的,容器是动态的。
docker镜像是分层存储的,最开始要指定一个基础镜像,我们每做一次修改就会在原本的镜像存储层上多搭一层,记录这个更改;而新搭的这层是静态、且可以持久化存储的。docker镜像的每一层都可以被不同镜像共同使用,如果某几层镜像本地已经有了,再去pull的时候就不会再拉已经有的镜像层了
容器也是相同的存储架构,但是每次修改新搭的一层是动态的,而且并不是持久化存储的;当容器被删除,或者重启计算机(内存断电)之后,容器没了,相应的这些容器存储层也没了。所以我们在容器上进行了修改,想要保存下来这个修改的话必须commit成静态的镜像。(或者用volume,链接到宿主)
docker-compose
多个docker之间要相互合作,比如nginx、mysql、nextcloud每个组件都在一个容器里,那我就需要docker-compose。将项目需要哪些镜像,每个镜像怎么配置,要挂载哪些volume等等信息都写在docker-compose.yml里来实现容器的协同工作
阅读参考(这个写得很详细了,具体配置和指令见此文):Docker:Docker Compose 详解
在docker-compose中会指定多个dockerfile,且会指定该dockerfile生成的镜像的端口容器端口:宿主端口的映射(注意勿忘了必须在dockerfile里配置要暴露的端口)
# 在 docker-compose.yml 所在路径下执行该命令 Compose 就会自动构建镜像并使用镜像启动容器
docker-compose up -d
docker-compose ps
docker-compose logs
docker-compose build
docker-compose start
docker-compose stop
docker-compose rm
docker-compose up
docker-compose kill
docker-compose run
docker-compose scale模板(参数可选):
version: '2' # 表示该 Docker-Compose 文件使用的是 Version 2 file
services:
server-docker-name1: # 指定服务名称
build: . # 指定 Dockerfile 所在路径,如果没写下面三个子项就可以只写这里
context: ./dir
dockerfile: Dockerfile #对象
args:
image: #指定镜像
ports: # 指定端口映射 <宿主>:<容器>
volumes: #设置volumes
dns:
dns_search:
environment: #环境变量
env_file: #环境变量文件
expose: #暴露端口,只将端口暴露给连接的服务,而不暴露给主机
network_mode: #设置网络模式
links: #将指定容器连接到当前连接,可以设置别名,避免ip方式导致的容器重启动态改变的无法连接情况
volumes: #卷挂载目录
logs: #日志输出信息
server-docker-name2:
# xxxxxx 和前面一样SOA和微服务
SOA
SOA=Service Oriented Architecture,面向服务的架构
SOA是一种设计方法,其包含多个服务,而服务之间通过相互依赖配合最终会提供一系列功能。一个服务通常以独立的形式存在于操作系统进程中。服务之间通过网络调用,而非采用进程内调用的方式进行通信。
显然SOA通过REST RPC等手段进行的“调用”,比依赖注入还更解耦,进一步降低了服务耦合
如何通俗易懂地解释什么是SOA? - 光太狼的回答 - 知乎 https://www.zhihu.com/question/42061683/answer/251131634
ESB(企业服务总线)是SOA里的概念,简单来说 ESB 就是一根管道,用来连接各个服务节点。为了集成不同系统,不同协议的服务,ESB 做了消息的转化解释和路由工作,让不同的服务互联互通
微服务
随后SOA演变出一种微服务架构。微服务要求“业务需要彻底的组件化和服务化”,原有的单个业务系统会拆分为多个可以独立开发、设计、运行的小应用。这些小应用之间通过服务完成交互和集成。
容器技术大大帮助了微服务,因为容器就是可以独立开发、设计、运行,不依赖其它东西的小单元
而在微服务中替代SOA中ESB的就是API网关了,向外暴露出API接口
微服务是SOA的子集,一种实现方式
Java EE部署架构,通过展现层打包WARs,业务层划分到JARs最后部署为EAR一个大包,
而微服务则打开了这个黑盒子,把应用拆分成为一个一个的单个服务,应用Docker技术,不依赖任何服务器和数据模型,是一个全栈应用,可以通过自动化方式独立部署,每个服务运行在自己的进程中,通过轻量的通讯机制联系,经常是基于HTTP资源API,这些服务基于业务能力构建,能实现集中化管理
参考:https://zhuanlan.zhihu.com/p/88095798
敏捷开发&Scrum&CICD&DevOps
敏捷开发&Scrum
Scrum是一种敏捷的开发过程框架:敏捷,即强调加快交付速度,变革的持续性。
持续——随时可运行。
CI&CD
CI(持续集成,Continuous Integration):在源代码变更后自动检测、拉取、构建和(在大多数情况下)进行单元测试的过程。四大特点:频繁发布,自动化流程,可重复,快速迭代。
自动化流程:关键是用自动化流程来处理软件生产中的方方面面。这包括构建、测试、分析、版本控制,以及在某些情况下的部署。
频繁发布:如果我们把某个历史版本的代码作为输入,我们应该得到对应相同的可交付产出。
单元测试:由开发人员编写的小型的专项测试,以确保新代码独立工作。“独立”这里意味着不依赖或调用其它不可直接访问的代码,也不依赖外部数据源或其它模块。
由于这与持续集成工作流有关,因此开发人员在本地工作环境中编写或更新代码,并通单元测试来确保新开发的功能或方法正确。通常,这些测试采用断言形式,即函数或方法的给定输入集产生给定的输出集。它们通常进行测试以确保正确标记和处理出错条件。有很多单元测试框架都很有用,例如用于 Java 开发的 JUnit。
CD(持续交付,Continuous Delivery):通常是指整个流程链(管道),它自动监测源代码变更并通过构建、测试、打包和相关操作运行它们以生成可部署的版本,基本上没有任何人为干预。
持续交付管道:将源代码转换为可发布产品的多个不同的 任务(task)和 作业(job)通常串联成一个软件“管道”,一个自动流程成功完成后会启动管道中的下一个流程。
监测程序通常是像 Jenkins、CodePipeline(阿里云)这样的应用程序,它还协调管道中运行的所有(或大多数)进程,监视变更是其功能之一。监测程序可以以几种不同方式监测变更。这些包括轮询(监测程序反复询问代码管理系统)、定期、推送
想象一个多条流水线的工厂来理解,所有流水线连接在一个机器人上,不同流水线对应机器人身上不同的组件,各个组件持续集成,持续交付。
DevOps
运维开发(DevOps) 是关于如何使开发和运维团队更容易合作开发和发布软件的一系列想法和推荐的实践。
持续交付管道是几个 DevOps 理念的实现。
三者关系
敏捷专注于在加速交付的同时突出变化的过程。
CI/CD 专注于软件生命周期内强调自动化的工具。
DevOps 专注于强调响应能力的文化角色。
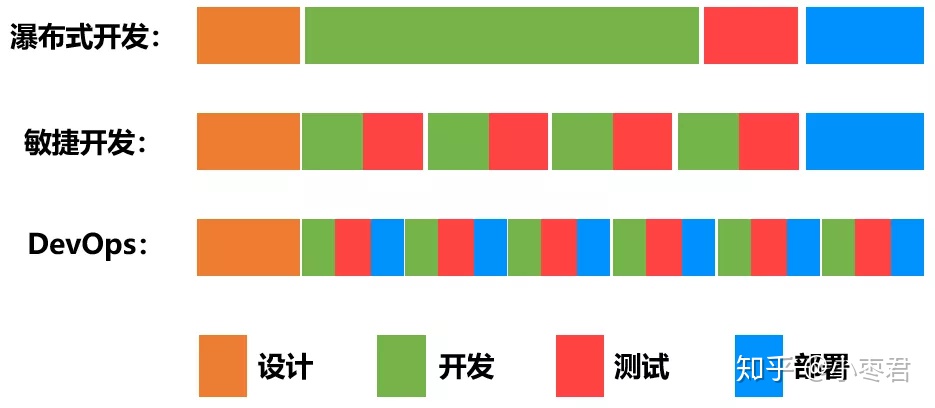
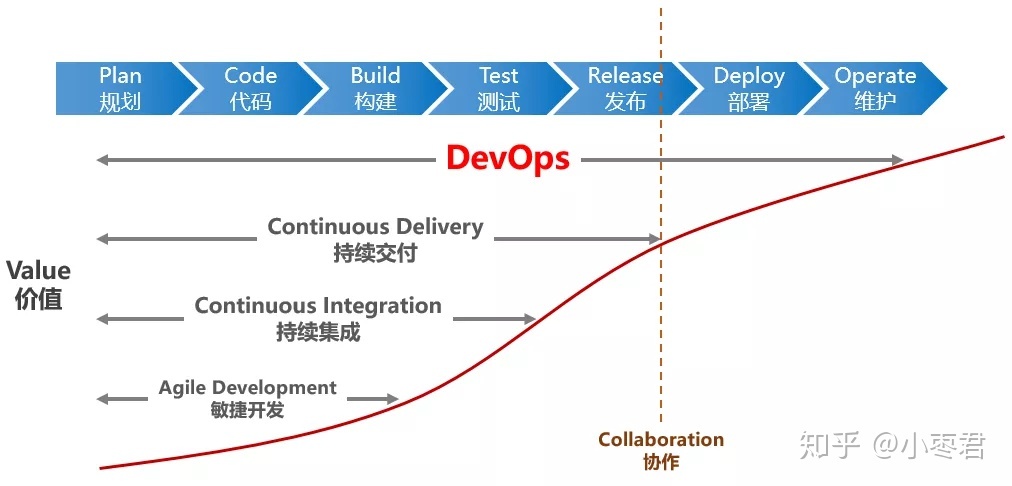
图来源:DevOps到底是什么意思?
可以看得出,容器技术使得开发环境各个组件和部署环境都可以更好地隔离了,减小了相互之间的影响,大大助力了敏捷开发、CICD、DevOps开发模式。



