

《Adversary Resistant Deep Neural Networks with an Application to Malware Detection》
Qinglong Wang ,Wenbo Guo,Kaixuan Zhang,AlexanderG.OrorbiaII, Xinyu Xing,Xue Liu,C.LeeGiles
KDD 2017(CCF-A)
Introduce
deep neural networks(DNNs) could help turn the tide in the war against malware infection
However, DNNs are vulnerable to adversarial samples
- Past research in developing defense mechanisms relies on strong assumptions,which typically do not hold in many real-world scenarios. Also,these proposed techniques can only be empirically validated and do not provide any theoretical guarantees. This is particularly disconcerting when they are applied to security-critical applications such as malware detection.
Why It Works?
- 随机性的引入使得attackers不容易发现DNN的”blind spots”(也就是AEs)
- 这个adversary-resistant DNNs 只需要一点微小的工作,且可以维持分类的表现
- 从理论上来说,本文的方法可以保证对AE的抵抗性
该方法也可以应用在图像等其他DNN模型适用效果较好的领域
Related Works
Data Augmentation
Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014).
Towards deep neural network architectures robust to adversarial examples. arXiv:1412.5068 [cs] (2014).
Unifying Adversarial Training Algorithms with Flexible Deep Data Gradient Regularization. arXiv:1601.07213 [cs] (2016).
增强数据,主要是通过将潜在AEs与普通样本进行训练(对抗训练)以增加对AEs的鲁棒性,对抗训练已被证明很有用
作者指出的问题:blind spots空间太大,不可能去覆盖一个infinite space,且attackers也可以对对抗训练模型本身进行攻击(how),考虑到无限空间,每一次遇到AEs就必须再次训练对抗训练模型,如此反复迭代
Enhancing Model Complexity
增加模型复杂度
Towards deep neural network architectures robust to adversarial examples. arXiv:1412.5068 [cs] (2014).
Distillation as a defense to adversarial perturbations against deep neural networks. arXiv preprint arXiv:1511.04508 (2015). (防御蒸馏机制,将第一个深度神经网络输出的软标签输入到第二个网络中进行训练,降低模型对微小扰动的敏感度。第一个模型的软标签熵编码了类之间的相对差异)
作者指出的问题:攻击者可以使用两个近似性能的DNN来拟合整个机制(该论文作者承认了此机制很容易被拟合)
同时该机制实际上是一个梯度掩码模型,并无法抵抗JSMA的攻击
Random Feature Nullification
we introduce random feature nullification to both the training and testing phases of DNN models, making the architectures non-deterministic.
引入随机性,对行为特征进行随机失活,看起来像是一种特殊的dropout正则
但区别在于dropout仅仅在训练的时候对神经元随即失活,而本文的方法是在train和test的时候都执行
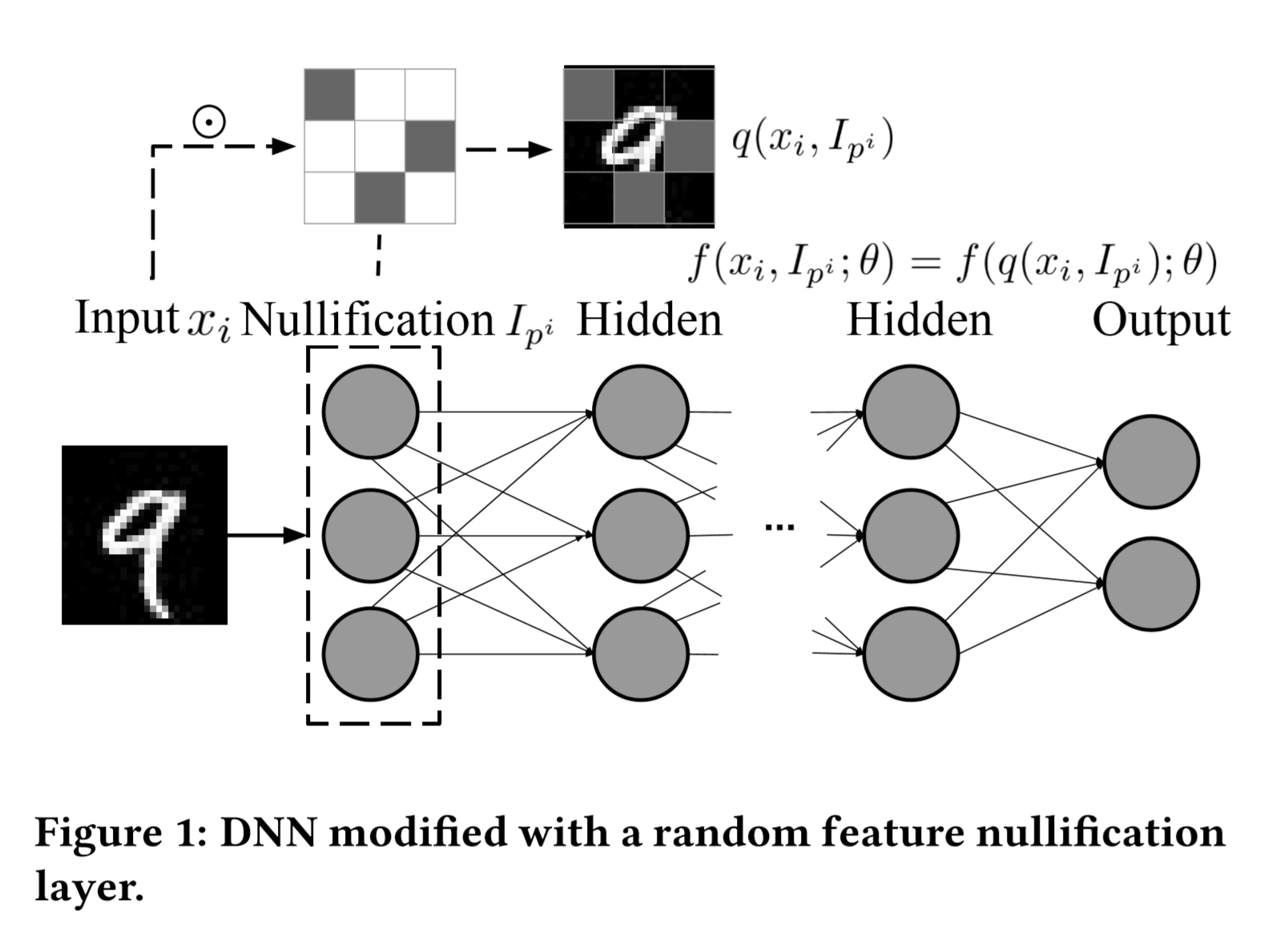
作者在input与hidden之间加了一层Nullification层
超参数:$μ_p,\sigma^2_p $
Model Description
$X\in R^{N*M}$ ($N$ 个样本,$M$维特征)
$\hat{I}_p\in R^{N*M}$ (mask matrix)
Nullification来源于$X$与$\hat{I}_p$按位乘
经验证在Random Nullification中会损失有用的分类特征信息,于是为了解决这个问题,本文为每个样本引入了Nullification Rate:$p^i$,且不仅哪个神经元失活是随机的,失活神经元的数量也是随机的
单个输入$x_i$对应一个$I_{p^i}$,后者是一个二进制向量,0的数量取决于$p^i$,且随机分布。作者使用了高斯分布和均匀分布。
$⌈M·p^i⌉$ :$I_{p^i}$中随机分布的0的个数,$p^i$是从高斯分布$N(μ_p,\sigma^2_p)$中的一次采样样本
于是DNN的目标函数定义为
随机特征失活过程(random feature nullification process)表示为$q(x_i,I_{p^i})=x^i⊙I_{p^i}$
(⊙为Hadamard product,一种特殊的矩阵乘法,同阶矩阵,$c_{ij}=a_{ij}*b_{ij}$)
于是$f(x_i,I_{p^i};\theta)=f(q(x_i,I_{p^i});\theta)$
在训练中使用SGD求解目标函数,但这里不同之处在于$I_{p^i}$在一个样本的前向传播和反向传播过程中是固定的,这使得容易计算$L(f(x_i,I_{p^i};\theta),y_i)$的导数
在测试中由于参数固定,使用高斯分布$N(μ_p,\sigma^2_p)$的期望作为辅助的随机变量$p^i$
Analysis: Model Resistance to Adversaries
攻击防御:
对抗攻击需要求解如下导数($\hat{x}$是任一测试样本)
where $J_L(q)=\partial L(f(x_i,I_{p^i};\theta),\hat{y})/\partial q(\hat{x},I_p)$,$I_p$是在测试中使用的mask matrix
只要此式子求解,攻击者便可以生成AE发动攻击$\hat{x} \to\hat{x}+ \phi sign(J_L(\hat{x}))$
但此时由于乘随机变量$I_p$的存在,使得攻击者无法轻易算出$J_L(q)$
这里作者说明了如果$I_p$是加随机变量的话$J_L(q)$将可以被轻易求解
模拟攻击:
因此,攻击者要想攻击此模型的最佳办法就算去拟合$I_p$.
作者假设 $I^*_p$ 为 $I_p$ 的最佳拟合,DNNs为黑盒,最佳的扰动为 $\delta\hat{x}$
则最佳合成攻击样本为 $\hat{x}+\delta\hat{x}⊙I^*_p$
假设攻击者用此来攻击下面图2中的系统
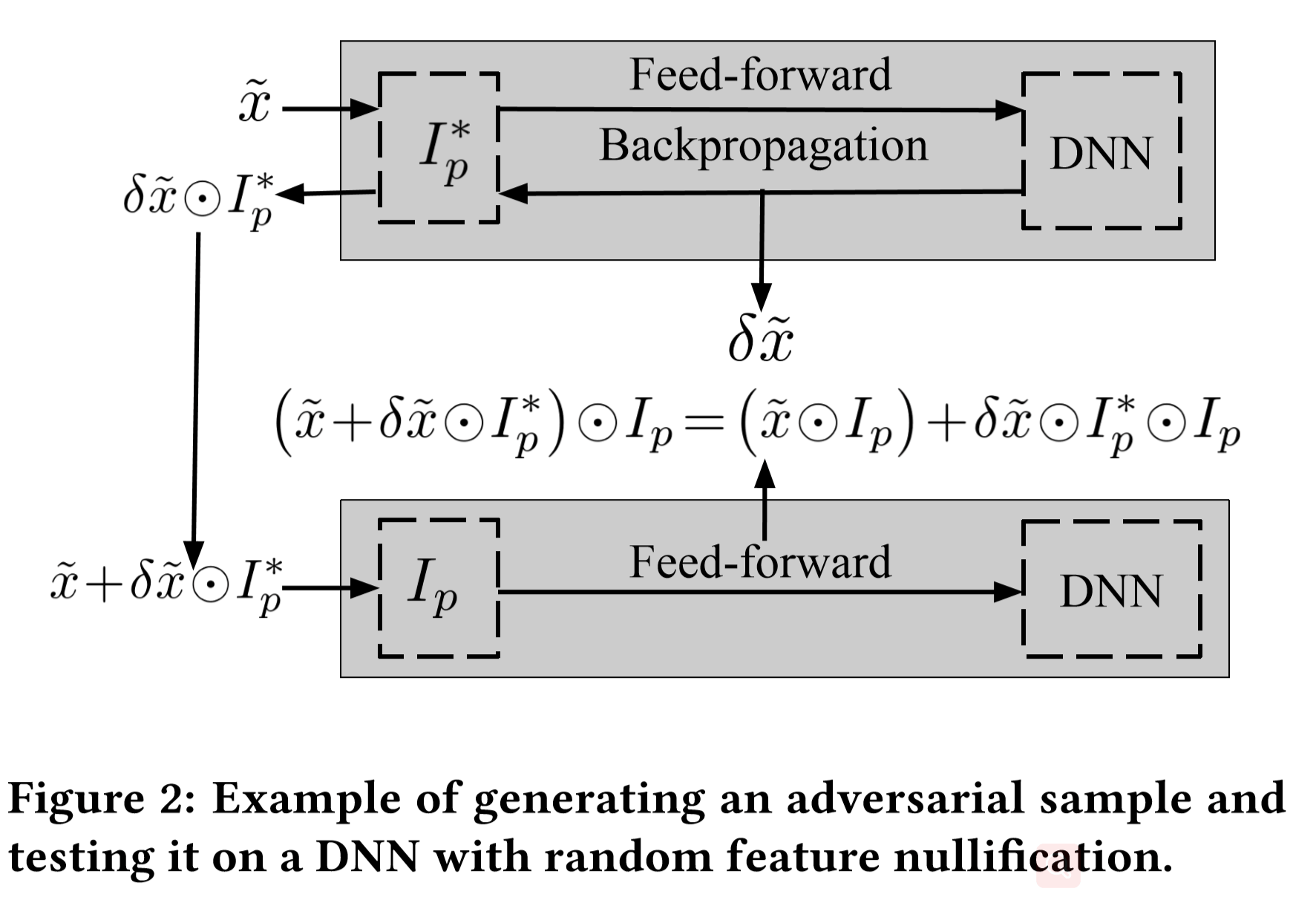
如图可以看到,攻击必须经过feature nullification layer才能抵达实际的DNN,由如下式子表示
式子中 $\hat{x}⊙I_p$ 即为一个真实的nullified样本,$\delta\hat{x}⊙I^*_p⊙I_p$ 就是发动攻击的添加的扰动
这里可以看到,尽管 $\delta\hat{x}$ 是非常有效的扰动,但 $I^*_p⊙I_p$ 的存在使得该扰动大幅减弱


