

再探
递归树:描述递归的问题结构
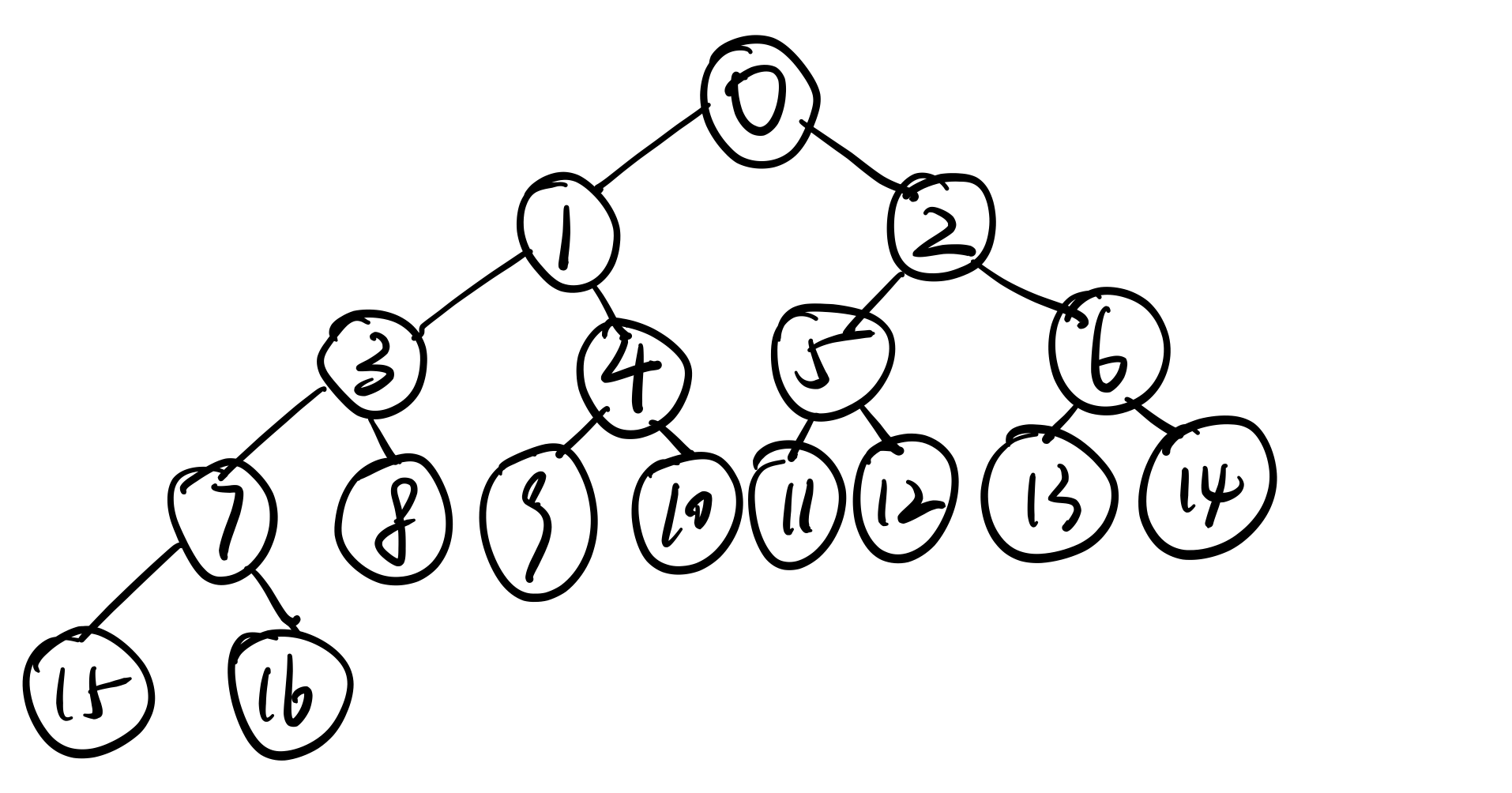
递归树可以用如下图表示,这个树描述了递归的问题结构(二分递归)
对于先左后右,出栈执行(倒序执行)的递归(后序续历),如下设计:
void func()
{
if (left可递归)
func(left)
if (right可递归)
func(right)
执行体(访问)
}执行过程:[入]0、1、3、7、15 [出]15 [入]16 [出]16 [出]7 [入]8 [出]3 [入]4 [入]9 [出]9 [入]10 [出]10 [出]4 [出]1 [入]2、5、11 [出]11 [入]12 [出]12 [出]5 [入]6、13 [出]13 [入]14 [出]14、6、2、0
所以对于通过前中序序列来还原二叉树的问题,即可通过前序序列找到子问题个根节点,再通过中序序列找到左右节点的顺序(因为前序遍历是访问到子问题的根节点的时候就输出,中序遍历的输出顺序是左中右)
核心:在递归问题中,不变的就是要理清大问题和小问题,拥有“局部”的眼光,只看当前问题,不看以前的问题,将子问题封装成一个整体。一个递归是一个进入跟结点后的子问题(递归函数体),只解决了以这个结点为根节点的子问题,左右结点都是下一层递归的问题!左右结点就是左右子问题,和本层节点一样,自会去执行各自的子问题(比如输出data域,如果其下还有子问题,必然会有相应的输出,但不需要在目前这个问题管),所以不用管,看成一个整体即可。于是对于中序遍历,一个子问题就是:左递归完成,然后输出本节点data域,再进入右节点子问题——对于每一个子问题,都是先输出左边(不管,继续递归的子问题)再输出中间(本层)再输出右边(不管,继续递归的子问题)(对于最小子问题,就需要结束递归了,即最终出口)
结合代码去想,这个函数即为进入一个根节点所对应的一个子问题的执行过程。
几个要点与理解
①每一个子问题都满足该函数内部的内容
②必须有子问题递归条件
对于子问题,判断是否继续递归(即上面中的if语句),否则就停止该子问题的递归,出栈该子问题(注意,出栈的是该子问题,不再继续递归该子问题)
②执行体:解决子问题所进行的操作;在二叉树的深度遍历中,称作“访问结点”
执行执行体:解决该子问题
③a.子问题出栈的时候即解决该子问题(倒序执行)
在二叉树深度遍历中相当于后序遍历
void func()
{
if (left可递归)
func(left)
if (right可递归)
func(right)
执行体(访问)
}b.若要让子问题入栈的时候即解决该子问题(正序执行),则如下设计:
在二叉树深度遍历中相当于前序遍历
void func()
{
执行体(访问)
if (left可递归)
func(left)
if (right可递归)
func(right)
}④递归树中父节点与子节点的关系
递归的不同层次(父问题与子问题)
⑤只有当子问题全部出栈(执行执行体,即解决问题),父问题才会出栈(执行执行体,即解决问题)
以上面递归树例子为例,对于7的子问题,[入]7,代表开始解决7问题了,这时候递归7问题,发现7还有子问题,于是 [出]15 [入]16 [出]16,这时候7的子问题全部出栈(全部解决完),这时候再 [出]7(解决父问题:7)
基于思想灵活变通
基于以上的要点思想,进行灵活的递归设计
但是有几个核心要明确:①子问题继续递归条件②执行体
(或者说:①递归最终出口(递归树叶子结点)②下一层递归入口③当层递归出口执行体;执行体可以在下一层递归入口之前(相当于前序),也可以没有单独的递归最终出口,直接在下一层递归入口处判断即可)
脑子要清晰,我现在处于哪一层的子问题,现在的环境变量,各个变量现在是什么(因为多个子问题,很容易搞错),要结合递归树、子问题、栈、执行过程仔细思考
举例:归并排序的递归结构
在归并中,执行体为Merge,但最小子问题(即划分为只有一个数的时候)是不用Merge的
也就是说执行体也有条件(即Left<Right),叶子结点不用执行Merge操作,与递归条件是一样的(叶子结点不用再继续递归)
那么我们就将执行体写如递归判断条件中去!
void sonMergeSort
{
if (left<right)
{
int mid = (left+right)/2;
//递归入口1
sonMergeSort(array,left,mid);
//递归入口2
sonMergeSort(array,mid+1,right);
//执行体
Merge(array)
}
}假设现在序列中某处子问题序列是(2,1),那么回归到递归树上,将子问题与问题内容一一对应
[7]=(2,1),[15]=(2),[16]=(1)
那么递归栈将会[入]7 [出]15 [入]16 [出]16 [出]7
出栈即执行执行体,而对于[15]和[16]问题,我们判断不符合Left<Right,那么就不会执行Merge,不做任何事就出栈
于是就到了[出]7,在子问题[7]中,环境变量中有left,mid,right,当然满足left<right,于是我们就要对left~mid和mid~right执行merge操作
易误解
我自己的一个误区:递归并不是并发进行的,而是逐层进出栈,整个递归调用的顺序是线性的一条链。所以完全可以用一个全局变量来记录当前递归信息
二分查找是不需要递归来做的,外面一个循环,内部进行分治查找
二叉树的叶子结点有个虚的null结点,这样思考会更好一些
并不是出栈即执行,结合代码思考


