

linux存储栈
用户请求(流数据)-文件系统转换成块设备需要的块(块数据)(在内存中进行)-发送到设备(BIO方式) =>完成将数据写到磁盘
内存在这个过程中扮演磁盘缓存,将这一流程分为上下两个异步过程
流 Stream;块 Block
【Pic:The Linux Storage Stack Diagram】
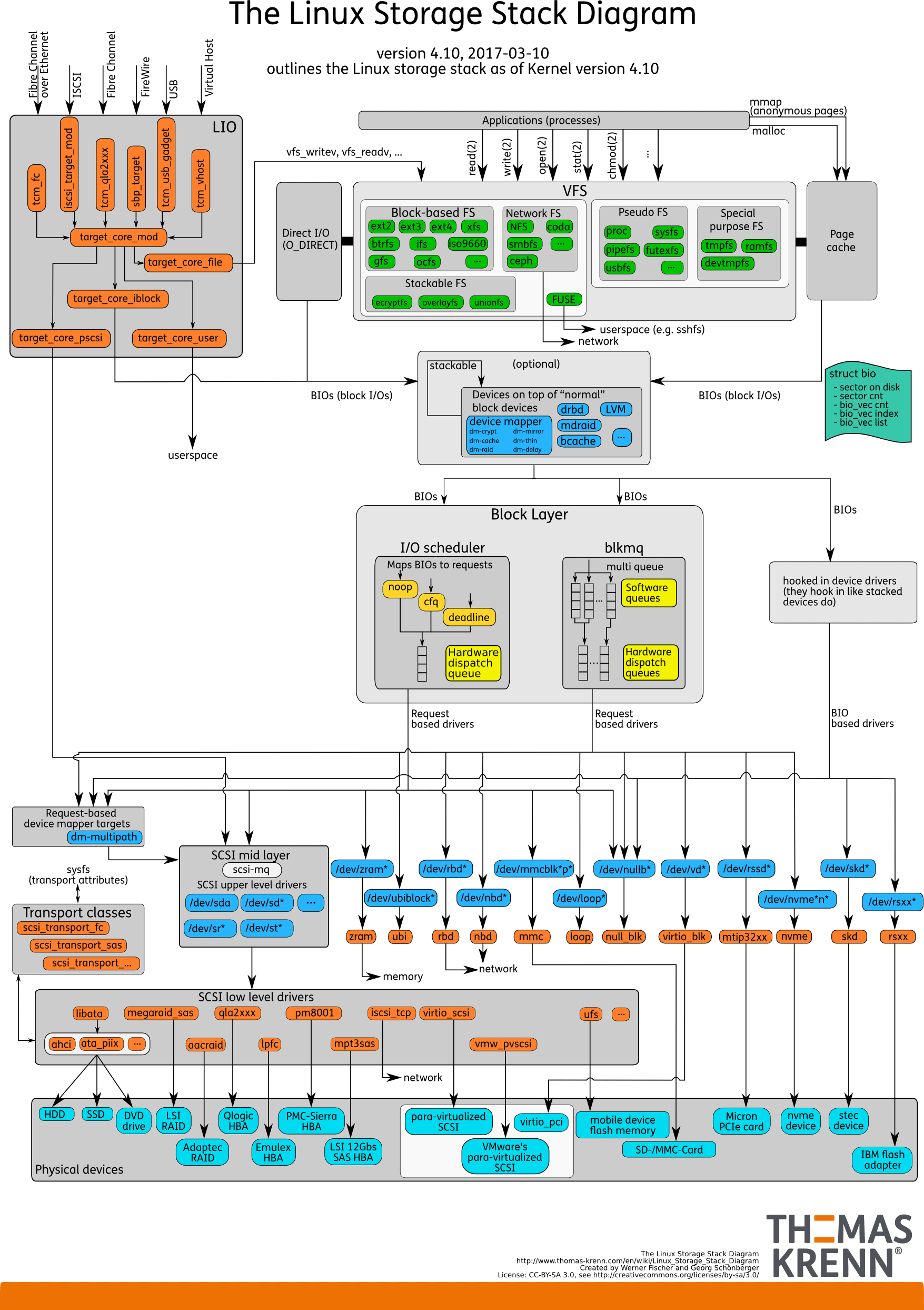
此图为关键,包含linux存储栈所有内容
内存区域中,低位地址是用户态应用,高位地址给内核态应用(32位支持4G内存,低位3G用户态,高位1G内核态)
pmap:查看进程的地址空间分布(or /proc/<pid>/maps查看)
mmap/mmap2:将文件中指定长度的一段数据映射到指定内存区域,从而可以通过访问内存的方式访问文件;且设置参数可支持贡献映射,私有映射,匿名映射等)
使用mmap访问内存,相比read/write,减少了一次用户空间到内核空间的映射(即直接访问内存来访问文件),提升性能
(lab)
用户态与内核态,是权限的差别
凡是与硬件有关的(比如内存),以及操作系统级别的,都是属于很高的权限,都是系统调用
系统调用从执行的时候就进入内核态,返回的时候才回到用户态
文件系统
VFS(Virtual File System)虚拟文件系统向用户提供统一的抽象系统调用供用户使用,屏蔽真实文件系统细节;各个真实文件系统需要遵循VFS提供的规范才能兼容,常见的真实文件系统有Ext3、NFS、ISOFS等。
VFS主要有四个对象类型:
- 超级块:存储文件系统相关信息
- inode:存储文件(含目录)的元数据,一个文件对应一个inode,包含指向文件(目录项)数据的指针(或文本数据)
- 目录项(也是文件,一种特殊的文件):描述了文件系统的层次结构,主要格式为[目录—-文件名(含目录项)—-inode]
- 文件
linux一切皆文件,一切文件皆有一个对应的inode结点,后面就不特意强调目录项也是文件了
Btrfs特性
BTree
Ext3额外使用BTree,当同一目录下文件容量超过2KB,这个目录的inode的i_data域(i_data域用于存放数据,目录的i_data域原来是没数据的,文本数据会直接存在其inode的i_data域(?))会指向一个BTree结构的目录索引,通过检索这个BTree可以快速找到目标文件的inode编号
Btrfs就是更进一步进化,其所有inode结点都是只通过BTree索引
一切文件的索引从超级块开始
对于文件系统来说,假设用树结构进行索引,树的每个结点就是一页,在搜索树的时候,每访问一个结点,实际上都要进行一次IO,从磁盘读数据到内存,所以树越高,IO越多,所以我们用BTree,很扁平,IO很少(还有局部预读优势)
extent
inode中保存有指向数据块的指针,现代文件系统(如ext4、Btrfs)通常用extent来取代block(块),一个extent由很多连续的block组成,减小元数据的开销。
动态索引节点分配
ext234的索引节点数量都是固定的,存在索引节点用完但磁盘空间没用完的情况,Btrfs则是动态分配
SSD优化(?)
支持元数据和数据的校验
支持写时复制
子分区subvolume
软件磁盘阵列
压缩
page cache
计算机存储结构:扇区->块(簇,block)->页
扇区:磁盘上的最小寻址单位,通常为512B
块:文件系统读写数据的最小单位,也叫磁盘簇,Block。操作系统内核不能对磁盘扇区直接寻址,而是对块进行寻址
页:内存的最小存储单位
块由扇区组成,页由块组成
page cache,文件缓存,属于内核缓冲区,缓存页,在内存中;(注意与MMU管理的page table的区别,而TLB在CPU缓存中,这俩存的都是地址转换表,而page cache在内存中缓存的是page/block)在2.4.10版本内核之前有个buffer cache,用来缓存块,现在已经被包含在page cache里了;其主要作用是内核将闲余的内存空间利用起来对磁盘文件进行缓存(预读)
【更深入了解】
DDIO(Data Direct IO)
跳过page cache,不经过内存直接进行块设备与CPU之间的数据传输
见下面“关于SPDK&DPDK”一节
所以IO也分为Direct IO和Buffered IO
块层(Block Layer)
块设备复杂程度高,且块设备访问性能对系统影响很大,所以内核专门提供了一个子系统来管理块设备,叫Block Layer
块层属于真实磁盘文件系统与IO调度层之间
内核设备IO流程:
【虚拟文件系统】—-【(page cache)】—-【真实文件系统】—-【通用块层】—-【IO调度层】—-【块设备驱动】—-【块设备】
通用块层:通用块层通过bio结构向IO调度层描述IO请求,这里已经到达了物理磁盘领域
IO调度层:对通用块层的请求进行优化调度处理(如合并等),再使用request结构体向下层块设备驱动发出请求
bio结构描述了真实操作位置(块设备上)的块与Page Cache(内存中)中块的映射关系,一个bio在磁盘中对应一块连续的位置,但其对应的内存中的数据可以不连续,由若干bio_vec来描述(一个bio对应多个bio_vec,一个bio_vec描述一个块在哪个page中的哪个位置)
多个bio在块层被合并(蓄流->泄流)为一个request结构,request组成request队列,调用设备驱动程序接口将request移动到设备驱动层进行处理;一个块设备有若干request队列与之对应(一个队列一个CPU处理)
IO调度有多种算法,如noop(FIFO)、deadline(电梯+最大等待时间防饥饿)、CFQ(多请求队列、时间片;默认)
LVM(Logic Volume Manager)
逻辑卷管理
LVM解决传统磁盘分区不方便管理的问题(需要重新进行系统引导)
LVM通过device mapper建立逻辑设备到物理设备的映射,它对IO请求进行过滤或重定向等工作
LVM是可选的,见上面大图中Block Layer上面那个矩形框,就是LVM层,它在Block Layer(块设备)之前,被注册为一个块设备驱动
device mapper机制由内核空间的device mapper块设备驱动(提供映射机制)和用户空间的device mapper库(用户空间可以决定如何建立映射)组成
derive mapper块设备驱动则有三个重要对象概念:mapper device、target device、mapping table
LVM可以嵌套,即多层逻辑设备
bcache
linux内核的块层缓存,使用固态硬盘作为硬盘驱动器缓存
三种缓存策略:writeback、writethrough(default)、writearoud
bcache可以将固态硬盘池化,一个固态硬盘形成一个缓存池,对应多块硬盘驱动器,并且支持从缓存池中划分出瘦分配的纯Flash卷(thin-Flash LUN)单独使用。LUN是存储设备上可以被应用服务器识别的独立存储单元。
bcache被划分为很多bucket,使用LRU策略缓存,计数周期减少;需要GC,压缩无效bucket
块层缓存还有flashcache、dm-cache、enhanceIO等,前两者通过device mapper机制实现
DRBD(Distributed Relicated Block Device)
分布式块设备复制,用于通过网络在服务器之间对块设备进行镜像,以解决磁盘单点故障问题
类似于HA集群
两种工作模式:主从、双主
存储加速
关于syscall:read+syscall:write操作
read+write连续调用的场景是网络读盘:即读取互联网一台计算机的磁盘数据,需要先read从磁盘到服务端[内核缓冲区],再由服务端程序write从用户程序到网卡[套接字缓冲区]
磁盘缓冲—-(copy)—内存—(copy)—-用户程序缓冲区
CPU Direct:在原来的存储栈中,read操作是 数据先从磁盘拷贝到磁盘缓冲区,再由CPU从磁盘缓冲区拷贝到内核缓冲区(在内存中-内核态,高位),再由CPU从内核缓冲区拷贝到应用程序缓冲区(也在内存中,但是状态不同-用户态,低位);然后write则是将数据从应用程序缓冲区拷贝到套接字缓冲区,再从套接字缓冲区拷贝到网卡,这个过程全由CPU负责
一次syscall两次拷贝:指的是内存与用户之间往返的两次(内核缓冲区-用户缓冲区)
一次syscall两次状态切换:syscall进入与返回两次
read+write则是四次拷贝(CPU Direct全由CPU负责)、四次状态切换
CPU&DMA:这个方式下CPU不再与磁盘直接交互,而是CPU命令DMA去与磁盘交互(DMA负责磁盘与内存之间的数据拷贝,这是在内核态,CPU只负责用户程序与内存之间数据的拷贝),CPU就解放了一部分。但是这个方式下,还是存在2次DMA拷贝,2次CPU拷贝,4次状态切换(进出read、write)。
zero-copy 零拷贝技术:不进行两次两次拷贝,而是直接
mmap+write、sendfile、sendfile+DMA收集、splice、dpdk、spdk、rdma、NVMe Direct等
mmap可以做到共享内核缓冲区与用户空间缓冲区,减少了一次CPU拷贝(不需要内核缓冲区->用户空间缓冲区,只需要内核缓冲区->套接字缓冲区),且有状态切换
mmap小文件可能出现碎片,且多进程环境下可能出现问题
sendfile建立了两个文件之间的传输通道,一个syscall实现了read+write,减少了两次状态切换,数据不经过用户缓冲区。2次CPU拷贝,2次状态切换(进出sendfile)
由于数据不经过用户缓冲区,所以数据无法被修改;且sendfile只能将数据拷贝在socket上
sendfile+DMA 同理,改由DMA直接操作磁盘,2次DMA拷贝,2次状态切换
但需要DMA控制器
splice则是在sendfile+DMA上改进,不需要DMA控制器,且不再限定将数据拷贝到socket上
两个文件描述符参数中有一个必须是管道设备
关于DMA&RDMA
DMA(Direct Memory Access),可以把计算机主板上的设备数据直接传送到内存中,不需要CPU参与
RDMA(Remote Direct Memory Access),允许两台主机的应用程序(存储)在它们的内存空间之间直接进数据传输
RNIC:具有RDMA引擎的网卡(NIC:网卡)
数据传输路径:[host1的应用程序缓冲区]—-[host1的RNIC]—-NETWORK—-[host2的RNIC]—-[host2的应用程序缓冲区]
显然这样就不用经历两次IO缓冲区
RDMA相比传统的TCP/IP有很大优势,RDMA不需要CPU参与,在用户态进行,且数据流将被处理为离散消息进行传输,且可以分散/聚合多个流
RDMA特性:zero-copy,kernel bypass,无CPU干预,消息基于事务,支持分散/聚合条目
支持RDMA的网络协议:IB,RoCE,iWARP;这些协议都要求RDMA专用NIC
关于RDMA&DPDK
两者都不使用内核协议栈,都是使用自己的网络协议栈,也就实现了kernel bypass
RDMA是将协议栈下沉到网卡硬件,即由具有RDMA引擎的网卡RNIC来单独完成网络协议栈
DPDK是将协议栈上移到用户态软件,在用户态实现了网络协议栈
DPDK是软件层面实现的;RDMA则需要专用RNIC硬件支持
DPDK仍然会消耗CPU资源,并发度取决于CPU的核数;而RDMA的收包速率完全取决于网卡硬件的转发能力
DPDK在低负荷场景下会造成CPU空转;RDMA不会
DPDK用户可以自己定制协议栈;RDMA无法定制协议栈
关于DPDK&SPDK
DPDK关键技术:DDIO技术支持以太网控制器将IO流量直接传输到CPU高速缓存,不经过内存,UIO技术直接将设备数据映射拷贝到用户态、大页技术增大分页基本单位大小提高快表TLB访问命中率、利用CPU亲和性绑定网卡和线程到固定的core减少CPU任务切换、无锁队列减少资源竞争
SPDK关键技术:
32位linux系统的页面大小为4KB,DPDK中大页内存可以设置2MB或1GB,大页内存适合在程序占用内存很大的情况下,否则会浪费内存空间(程序占用内存小的话,调用却还是要以页为单位调入内存,页面过大就浪费内存了)
SMP&NUMA
主要是多核处理器及其内存系统的调度管理技术
SMP/UMA(Uniform Memory Access Architecture):一致性内存访问结构,所有硬件资源都是共享的,多个处理器没有区别、平等地访问内存和IO外部设备,并且每个处理器访问内存的任何地址所需时间是形同的。
缺点:扩展性有限,当内存访问达到饱和的时候,系统总线成为效率瓶颈,增加处理器也无用,且处理器与内存之间的通信延迟也增大
NUMA(Non-Uniform Memory Access Architecture):非一致性内存访问技术,设置多个处理器模块(Node),每个Node具有独立的本地内存、IO设备,处理器模块之间通过高速互联的接口连接起来。NUMA调度器负责将进程尽量在同一Node的CPU之间调度,除非负载太高,才迁移到其他结点。在设计包处理程序时,内存分配上使处理器尽量使用靠近其所在Node的内存,可以水平扩展包处理能力。
CPU加速
超线程技术:OS将一个物理核识别为两个逻辑核,它们有独立的寄存器,但是共用主要的执行单元
优化指令
SIMD(Single Instruction Multiple Data):单指令流多数据流指令,指拥有多个处理单元的计算机能够用一条指令(执行的流程)同时处理多个数据集;数据层次并行,一个寄存器可以作为完整的64位整数寄存器使用,也可以packed形式作为多个小的整数寄存器,如2个32位、4个16位、8个8位寄存器。
intel提出的AVX指令集就引入了三操作数SIMD指令,如AVX512把指令扩展到了512位,同时定义了32个512位寄存器,利用SIMD就可以操作位宽更大的寄存器,同时进行更多的向量计算
扩展指令(一些在存储上有用的)
如AES-NI指令集、CRC32扩展指令集、SHA-NI指令集
协处理器等其它硬件加速
- FPGA:定制化可编程芯片
- 数据密集计算加速:用FPGA实现纠删码、压缩算法、加密算法
- 存储协议转换的加速:在RDMA方案中,FPGA替代CPU卸载存储
- 特殊存储接口加速:用FPGA加速接口
智能网卡加速:将主机CPU上的工作放到网卡上来完成
Intel QAT(Quick Assist Technology):专注数据安全和压缩的硬件加速器,主要用于数据中心
- DVDIMM(Non-Volatile Dual In-Line Memory Module):一种可以随机访问的非易失内存
ISA-L(智能存储加速库)
包含数据保护、数据安全、数据完整性、数据压缩、数据加密等算法函数
ISA-L利用汇编语言编写,利用IA特性,使用高效的SIMD指令和专用指令,最大化利用CPU的微架构来加速存储算法的计算过程
细节略
SPDK(核心)
核心是用户态、异步、轮询方式的NVMe驱动,用于加速NVMe SSD
SPDK将内核驱动放到用户态,在用户态实现一个完整的存储栈(IO栈,见前面大节),其中一个重要话题就是文件系统,那么常见的文件系统如ext4、Btrfs都不能直接支持了。SPDK目前提供非常简单的文件系统BlobFS,但是并不支持可移植操作系统接口(POSIX,Portable Operating System Interface,是IEEE为要在各种UNIX操作系统上运行软件,而定义API的一系列互相关联的标准的总称),即由于SPDK的用户态IO栈的FS(File System,文件系统)不支持POSIX,导致应用程序不能直接从其它OS迁移到SPDK的FS上,所以应用程序需要一些代码移植工作来支持SPDK的用户态IO栈FS,或者采用AIO的异步读写方式,不使用POSIX
SPDK
SPDK NVMe驱动
Linux用户态驱动
UIO(userspace IO):linux专门提供的一套在用户态开发驱动的框架,它把硬件寄存器的地址用ioremap函数映射到用户态的虚拟地址(原理:UIO框架在内核中的小模块修改了页表),然后在用户态打开这个文件,mmap到内存中,我们就可以在用户态对硬件进行直接IO了,将大部分的内核空间操作放到了用户态
VFIO(Virtual Function IO):在UIO之上考虑到了安全,把设备IO、中断、DMA暴露到用户空间。引入IOMMU(IO Memory Management Unit)对设备进行限制,设备IO地址需要经过IOMMU重映射为内存物理地址来保证安全,这样物理设备将不能绕过或污染MMU(Memory Management Unit)。
用户态DMA:通过UIO或VFIO,就可以做到用户态驱动,在用户态发起对设备的DMA
用户态DMA三个要考虑问题:①提供设备可以认知的内存地址(设备支持IOMMU解决)②CPU对内存的更新必须对设备可见(CPU之间的缓存一致性来解决)③物理内存必须在位(人工pin解决不让换出解决,大页技术也可以缓解,因为大页可以使得页很少换出;大页技术还可以增大分页基本单位大小提高快表TLB访问命中率)
SPDK用户态驱动
SPDK基于UIO、VFIO技术,并引入了其它优化技术来提高用户态驱动对设备的访问效率
异步轮询
由SPDK用户态驱动对设备进行不断轮询,检查状态,判断是否操作完成,而不是让设备发起中断(因为中断由用户态进出处理不合适、给用户态程序引入不确定性)
无锁化
利用CPU亲和性绑定线程和特定CPU核心,并通过轮询的方式占住该核的使用,采用Run To Completion(运行直到完成)的方式,就可以避免资源分配上使用锁,一个核上只会有一个线程
单核上的资源依赖于DPDK的内存管理,不仅提供了核上的专门资源,还提供了高校访问全局资源的数据结构,如mempool、无锁队列、环等
专门为Flash优化
SPDK是专门针对NVMe SSD设备(Flash闪存)的,充分利用设备的高性能(低延时、高带宽),SPDK实现了一组C代码库。
但也支持块设备
SPDK用户态驱动多进程的支持
同一块NVMe SSD给多进程SPDK使用,NVMe SSD可以划分为多个Namespace或在同一个Namespace中划分多个空间分配给不同应用程序进程存储
共享内存(各进程标识)、共享NVMe SSD(数据通道上的隔离:NVMe设备的IO队列)、管理软件完成队列(共享给所有进程)
SPDK应用框架
SPDK提供了一个指导性的SPDK应用框架,用户可以选择使用SPDK应用框架,也可以自己使用SPDK用户态NVMe驱动提供的函数进行编程
对CPU core和进程的管理
设置绑定进程和CPU core,原则是用最少的core完成最多的任务,一个核上运行一个thread
thread在SPDK中封装为Reactor,SPDK为其封装了很多管理,比如Reactor的state没有改变之前,会默认执行while(1)不断轮询,运行直到完成
提供Poller机制为用户定义函数的封装,即thread执行的内容,一个thread可以执行很多poller
线程间的高效通信
放弃锁来进行线程间通信,SPDK提供了事件调用(Event)机制,每个Reactor对应的数据结构维护了一个Event事件的环,这个环是多生产者和单消费者模型(MPSC),每个Reactor thread可以接受来自任何其他Reactor thread的事件消息进行处理
IO的处理模型和数据路径的无锁化机制
包括SPDK用户态存储栈(可以理解为SPDK应用框架的一个应用)的实现也是使用了SPDK应用框架的设计,来达到最高的性能
SPDK用户态块设备层
在通用块层引入逻辑上的IO Channel来屏蔽下层的具体实现,IO Channel:Thread:Core=1:1:1
SPDK Bdev(SPDK快设备层)有以下几类核心的数据结构:①通用块设备的数据结构②操作通用设备的函数指针表③块设备IO数据结构
这些核心的数据结构,提供了最基本的功能上的特殊性来支持不同的后端设备,比如通过SPDK用户态NVMe驱动来操作NVMe SSD;通过Linux AIO来操作除NVMe SSD外的其他满速存储设备比如HDD、SATA SSD、SAS SSD等;通过Cpeh RBD来操作远端 Ceph OSD设备;通过GPT在同一设备上创建逻辑分区等等….
SPDK通用块层也使用了SPDK应用框架的优化思想来设计
与linux内核存储栈思想一样,SPDK用户态存储栈也引入IO队列,提供很多功能比如限速流控,IO分发,异常恢复等等
SPDK基于通用块层进行流量控制,好处是和上层各种协议、后端具体设备无关,可以是任何一个通用块设备。
SPDK用户态LVM的核心技术是Blobstore,其本质是一个block的分配管理,是位于SPDK Bdev之上的Blob管理层,用于与用户态文件系统Blobstore Filesystem(BlobFS)集成,代替传统的文件系统
P.S. Blob=Binary Large Object
具体略
【块设备层具体设计细节】
SPDK加速方案举例
【略】
SPDK vhost target
SPDK iSCSI Target
SPDK NVMe-oF Target
SPDK RPC
P.S. AHCI=Advanced Host Controller Interface
NVMe=NVMHCIS=Non Volatile Memory Host Controller Interface Specification



