

原论文:http://proceedings.mlr.press/v32/le14.pdf – Le & Mikolov, ICML 2014
evedroid算法用到了doc2vec来表征api的特征空间向量,看了一下doc2vec其实就是word2vec的DLC版。
doc2vec是将一篇文档转化为一个向量,word2vec是将一个单词转化为一个向量,doc2vec是基于word2vec的,论文作者将word2vec方法扩展到了句、段,甚至文档,将其嵌入到向量空间。本文句子实际就可代替文档。
doc2vec支持不定长输入
最基础的一种想法是直接将整句话词向量求和做平均,但这样的问题在于忽略了句子的结构和前后顺序,丧失了很多信息。
PV-DM
doc2vec中的PV-DM(Distributed Memory Model of paragraph vectors)对应word2vec中的CBoW
PV-DM在CBoW的基础上,输入不仅是一句话滑动窗口内的所有词,还有一个在一句话中共享的句子向量(Paragraph vector)
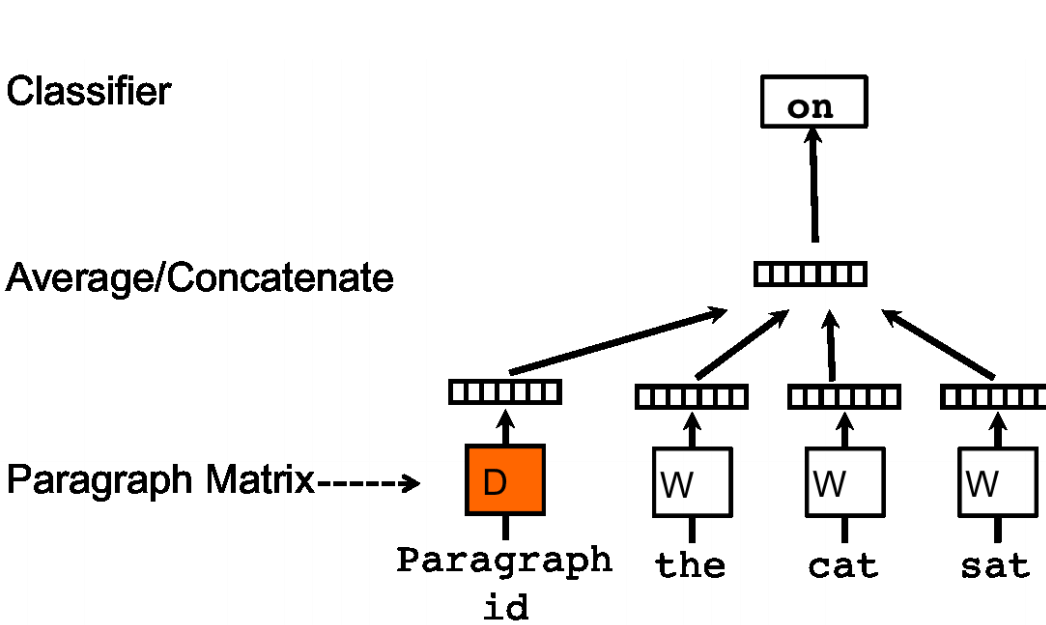
训练模型:在滑动窗口内的输入词中取其中一个为预测词;构造了一个新的向量,即句子向量(Paragraph vector);然后把句子向量和滑动窗口内所有one-hot词输入进模型:①句子向量用矩阵$D$表示,其作为训练参数,每一列代表一个句子,最开始要初始化;②one-hot词向量乘以输入词权值向量矩阵$W$,③然后线性求和得到隐藏的中间向量,④再乘以输出权值矩阵通过softmax激活,来预测预测词,与输入的预测词求损失,⑤通过反向传播梯度下降,训练结束后得到训练完成的$D,W$。
输入的句子向量保留了整个句子信息,相当于记忆。同一句话经过滑动窗口滑动,会有多次训练,每次训练中输入都包含上一次该句子滑动窗口使用的句子向量。
这个句子向量相当于这句话的“主题”。随着窗口的滑动,一句话训练多次,不断训练得到句子向量也会越来越准确,越能代表该句话
训练完模型之后,如何预测句子向量:实际上依然是要将初始化句子向量矩阵和词的one-hot向量输入模型,滑动窗口选词,句子向量矩阵共享,进行多次反向传播梯度下降,不断迭代调整句子向量权值矩阵,只不过输出权值矩阵$W’$和词向量都已经固定不变了,变的只有句子向量权值矩阵,而最终得到的结果这个句子向量矩阵。
PV-DBOW
doc2vec中的PV-DBOW(Distributed Bag of Words of paragraph vector)对应word2vec中的skip-gram
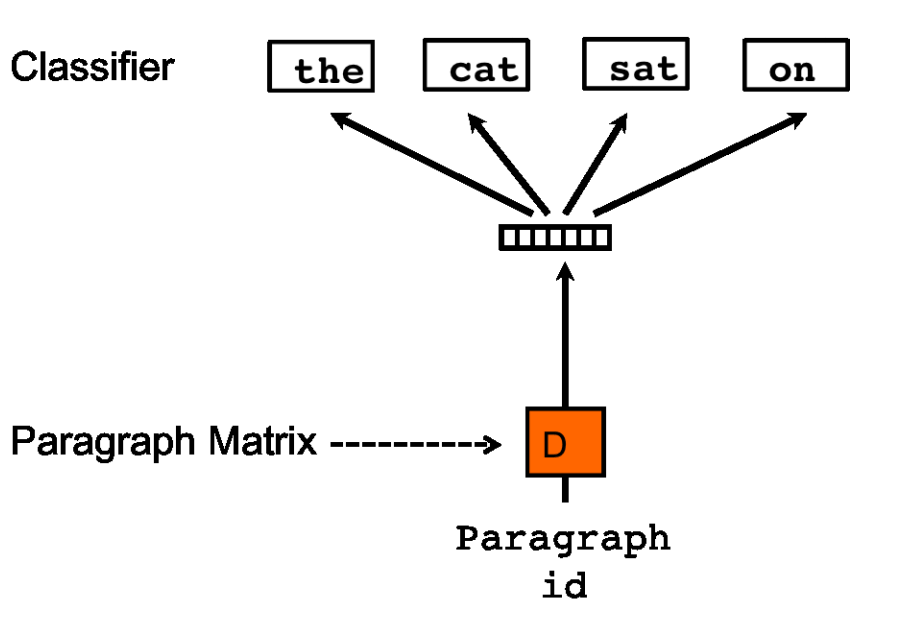
就,反过来呗
Doc2Vec的想法和RNN的想法很像
Tools
gensim库中有doc2vec


