

Conditional Random Field
在我前面的文章中有一些概率图模型的基础知识:深度学习中的结构化概率模型
如果数据量极大,配分函数有可能会遇到无法直接求和问题参看前文:配分函数,其中用到了蒙特卡罗方法,参看前文:蒙特卡罗方法
将概率无向图模型的联合概率分布表示为其最大团上的随机变量的函数的乘积形式的操作,称为概率无向图模型的因子分解(factorization)
标注问题:在条件概率模型$P(Y|X)$中,$Y$是输出变量,表示输出的标记序列(或状态序列),$X$是输入变量,表示需要标注的观测序列。注意被标注的是标记序列/状态序列,不是观测序列。HMM和CRF都可以用于标注问题(只是其中一个应用)。
条件随机场(conditional random field,CRF):给定随机变量$X$条件下,随机变量$Y$的马尔可夫随机场
线性链条件随机场(linear chain conditional random field,Linear-Chain CRF):定义如下
设$X=\{X_1,X_2,\cdots,X_n\},Y=\{Y_1,Y_2,\cdots,Y_n\}$均为线性链表示的随机变量序列,若在给定随机变量序列$X$的条件下,随机变量序列$Y$的条件概率分布$P(Y|X)$构成条件随机场,即满足马尔可夫性:
则称$P(Y|X)$为线性链条件随机场。意思是$Y_i$只与$X$(观测序列),$Y_{i-1},Y_{i+1}$有关
Linear-Chain CRF形式化表示
参数化形式
要先画状态路径图来理解公式
设$P(Y|X)$为线性链CRF,则在随机变量$X$的取值为$x$(状态序列)的情况下,随机变量$Y$取值为$y$(取值/观测值序列)的条件概率具有如下形式:
$i$就是序列位置标号,见上面Linear-Chain中的定义(设$q,p∈\Gamma$,$\Gamma$为$Y_i$的取值空间(观测空间))
$t_k(y_{i-1}=q,y_i=p,x,i)$,也写成$t_k(y_{i-1},y_i,x,i)$:特征函数,对应的权值为$\lambda_k$,定义为边上的特征函数,称为转移特征,依赖当前和前一个位置:[表示在第$i$位置上,序列第$i$位置$x$所对应的$y$取值(观测值)为$q$,到序列第$i-1$位置$x$对应的$y$取值(观测值)为$p$这条路径的转移特征,权值为$\lambda_k$]
$s_l(y_i=p,x,i)$,也写成$s_l(y_i,x,i)$:特征函数,对应的权值为$\mu_l$,定义为结点上的特征函数,称为状态特征,依赖当前位置:[表示在第$i$位置上,序列第$i$位置的$x$所对应的$y$的取值(观测值)为$p$的结点的状态特征,该结点的权值为$\mu_l$]
$k$表示边的转移特征函数数量,$l$表示结点的状态特征函数数量
一般特征函数$t_k,s_l$取值为0或1
此求和其实就是对所有路径求和(所有可能的输出序列)
举例理解:
对于$X=(X_1,X_2,X_3),Y=(Y_1,Y_2,Y_3),Y_i$的取值集合为$\Gamma=\{1,2\}$
可以得到一个二维图,横坐标$i_1,i_2,i_3$表序号,纵坐标$Y=1,Y=2$表$y$的两个取值
则图中所有坐标点(结点)为
$(Y_1=2,X,1),(Y_1=2,X,2),(Y_1=2,X,3)$
$(Y_1=1,X,1),(Y_1=1,X,2),(Y_1=1,X,3)$
如$(Y_1=2,X,1)$就表示在$i=1$的$X$序列位置上,$Y$的取值(观测值)为2,也可以写成$Y(X_1)=2$
然后就可以通过上面的结点和边特征函数以及权重将概率图绘制出来,一切求和就得出CRF的概率分布
其它形式
拼接$:K_1$个转移特征,$K_2$个状态特征,$K=K_1+K_2$
求和:对同一特征在各个位置求和(同一特征在不止一个位置上有定义)
$f_k(y_{i-1},y_i,x,i)=\begin{cases} t_k(y_{i-1},y_i,x,i),k=1,2,\dots,K_1\\ s_l(y_i,x,i),k=K_1+l;l+1,2,\dots,K_2\end{cases}$——①
组一:
$f_k(y,x)=\sum_{i=1}^n f_k(y_{i-1},y_i,x,i),k=1,2,\dots,K$ (对同一特征函数$f_k$在所有位置$\sum_i^n~$上求和)
$F(y,x)=(f_1(y,x),f_2(y,x),\dots,f_K(y,x))^T$(上面那个求和组成的向量,方便用于下面简化形式的内积形式)——③
组二:
$F_i(y_{i-1},y_i|x)=(f_1(y_{i-1},y_i,x,i),f_2(y_{i-1},y_i,x,i),\cdots,f_K(y_{i-1},y_i,x,i))$ (某一位置$i$下所有特征函数组成的向量)
$\therefore w·F_i(y_{i-1},y_i|x)=\sum_{k=1}^Kw_kf_k(y_{i-1},y_i,x,i)$ (与上上面的$f_k(y,x)$刚好反过来,先对一个位置$i$积分所有特征函数$f_k$,再积分所有位置$i$)——④
注意这一组的$F$下标和上面那组的含义是不一样的,一个是$k:$特征函数数量一个是$i:$位置数量
$w_k=\begin{cases} \lambda_k,k=1,2,\dots,K_1\\ \mu_l,k=K_1+l;l+1,2,\dots,K_2\end{cases}$——②
$w=(w_1,w_2,\dots,w_K)^T$
简化形式—对每个特征函数求其在所有位置的和
由②③:
$\therefore$特征*权重可以看成求正交化(内积)可以看成是先对每个特征函数$f_k$在所有位置$i$积分,再积所有特征函数$f_k$
矩阵形式—在每个位置求所有特征函数的和
由②④:
$W_i(y_{i-1},y_i|x)=\sum_{k=1}^Kw_kf_k(y_{i-1},y_i,x,i)$
$M_i(y_{i-1},y_i|x)=e^{W_i(y_{i-1},y_i|x)}$ (所以可以对每个位置$i$求$M$矩阵)
由于矩阵表示可以很直观的表示序列上每个位置的矩阵,所以很好用,下面概率计算的时候直接累乘即可
非矩阵形式可以表示为:(注意这个式子的$f_i(x,y)=$组二中的$F_i(y_{i-1},y_i|x)$)
此形式即最大熵模型形式!对Linear-Chain CRF参数的学习与对最大熵模型参数的学习一样
概率计算—求$\max\{P(Y_i=y_i|x)\},\max\{P(Y_{i-1}=y_{i-1},Y_i=y_i|x)\}$
与HMM一样使用前向-后向算法,递归计算,用矩阵形式表达方便
前向算法: 前向右乘$M$矩阵($\alpha^T$将原横着的序列变列向量与$M$矩阵相乘)
初始化:$\alpha_0(y|x)=\begin{cases} 1, y=start\\ 0,otherwise\end{cases}$
递推公式:$\alpha_i^T(y_i|x)=\alpha_{i-1}^T(y_{i-1}|x)[M_i(y_{i-1},y_i|x)],i=1,2,\dots,n+1$
后向算法: 后向左乘$M$矩阵
初始化:$\beta_{n+1}(y_{n+1}|x)=\begin{cases} 1, y_{n+1}=stop\\ 0,otherwise\end{cases}$
递推公式:$\beta_i(y_i|x)=[M_{i+1}(y_i,y_{i+1}|x)]\beta_{i+1}(y_{i+1}|x),i=0,1,2,\dots,n+1$
概率计算:
$P(Y_i=y_i|x)=\frac{1}{Z(x)}\alpha_i^T(y_i|x)\beta_i(y_i|x)$
$P(Y_{i-1}=y_{i-1},Y_i=y_i|x)=\frac{1}{Z(x)}\alpha_{i-1}^T(y_{i-1}|x)M_i(y_{i-1},y_i|x)\beta_i(y_i|x)$
其中$Z(x)=\alpha_n^T\vec1=\vec1\beta_1(x)$,$\vec1$为元素均为1的$m$维向量
[O]期望值计算:
$\mathbb E_{P(Y|X)}[f_k]=\sum_yP(y|x)f_k(y,x)=略$
$\mathbb E_{P(X|Y)}[f_k]=\sum_{x,y}P(x,y)\sum_{i=1}^{n+1}f_k(y_{i-1},y_i,x,i)=略$
学习算法—求模型参数$\hat w$
Linear-Chain CRF的位置求和形式,也即最大熵模型形式,于是可以用与MEM一样的方法来求模型参数
Improved Iterative Scaling
IIS,改进的迭代尺度法,具体略
注意模型参数是$w$,而$f_k$(或者全局特征向量$F(y,x)$)是先验参数!
经验概率$\hat P(X,Y)$即为在训练集上直接通过观测法求得的经验概率,如通过多次抛硬币频数法求得概率一样
极大化训练数据的条件概率对数似然函数:
$L(w)=L_{\hat P}(P_w)=\log\prod_{x,y}P_w(y|x)^{\hat P(x,y)}=\sum_{x,y}\hat P(x,y)\log P_w(y|x)$
将简化形式$P_w(y|x)$代入求极大
对其使用IIS,略
拟牛顿法
可以见我以前写的文章牛顿法求解非线性优化和拟牛顿法
直接对$P_w(y|x)$求对数似然得优化目标函数
依然使用简化形式$P_w(y|x)$
对其使用BFGS,略
预测算法—求$y^*=\arg_y\max P_w(y|x) $
给定输入序列/观测序列$x$,求条件概率最大输出序列$y^*$,即求$\arg_y\max P_w(y|x)$
与HMM一样的维比特算法,动态规划,注意递推式。
由于要确定路径,则使用在每个位置求特征和的积分方法,即上面的非矩阵形式公式,化简后可得:
求$\max_y\sum_{i=1}^nw·F_i(y_{i-1},y_i,x) $ (即求$\max_y ④$)
$F_i(y_{i-1},y_i|x)$为局部特征向量
递推式:$\max\{\delta_{i-1}+w·F_i(y_{i-1},y_i,x)\}$
具体略
HMM和CRF的对比区别
HMM是生成模型,CRF是判别模型
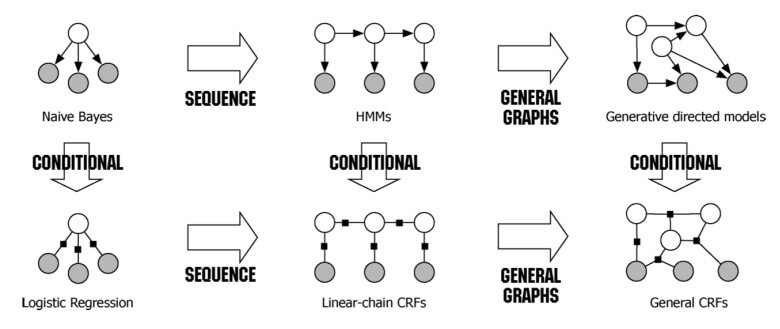
(本图来自知乎)
CRF的优化函数,可以做到全局最优
定义
CRF可以看成一组随机变量的集合,当给每一个位置按照某种分布随机赋予一个值之后,其全体就叫做随机场。这些随机变量之间可能有依赖关系 。
如果给定的马尔科夫随机场(MRF)中每个随机变量下面还有观察值,我们要确定的是给定观察集合下,这个MRF的分布,也就是条件分布,那么这个MRF就称为 Conditional Random Fields (CRF)。它的条件分布形式完全类似于MRF的分布形式,只不过多了一个观察集合X。所以, CRF本质上是给定了条件(观察值observations)集合的MRF。
HMM可以由CRF表达,CRF的范围更广。也就说,每一个HMM都可以被CRF表示
CRF要归一化而HMM不需要
因为CRF的权重值是任意的,而HMM是概率值必须满足概率约束条件
CRF可以依赖更多全局特征(Linear-Chain CRF的依赖也比较有限)
HMM只能依赖前一个状态和当前观测,而CRF可以定义更远的依赖关系
CRF可以看成MEMM(最大熵马尔可夫模型)在标注问题上的推广


