

以前做过几万数据求杰卡德相似度,计算要很久,多等等也能接受
但这次项目中有1000万样本…….每次比较计算杰卡德距离需要0.0015秒,算下来1000万样本需要计算………………………2379年(#捂脸)
所以找到了局部敏感哈希算法,可以有效加速大数据相似度比较计算
杰卡德相似系数
Jaccard相似系数用于求集合相似度
杰卡德距离:在占比中所取的是两个集合中不同元素。
注意:杰卡德的分母不包含$A与B$都没有的(都为0)的位置,分母只包含$A,B$元素为$11,10,01$的对
回顾hash分桶
一种解决hash冲突的办法。在hash值冲突的时候,多个原数据被映射到同一个哈希值,那么就将映射到同一个哈希值的原key放入一个桶中(链表形式储存),该hash值作为该桶的索引。查询的时候通过哈希计算找到对应的桶之后,沿着桶链表一个一个比较key是否相同即可。
min-hash
原始min-hash
hash就是让不同长度的文本转化为相同长度的一串字符串,即使只是差一位,生成的字符串也会天差地别
然而我们要计算相似度就需要相似的文本生成相似的hash字符串,这就是min-hash
从另一个角度讲hash其实就是将数据从原空间映射到一个新的低维空间,传统hash是使得新空间的向量分散,没有关系;而min-hash则使得在原空间距离较近的向量在新空间距离也较近,在原空间距离较远的向量在新空间距离也较远
具体地,min-hash就是将行(不同向量的每一个维度)多次随机打乱,找出第一个非零行的索引序号,作为最小哈希值$h(i)$
$n$次随机打乱后得到$n$个最小哈希值组成的序列$h(1),h(2),\cdots,h(n)$,此序列就是不同样本对应的哈希签名,显然向量越相似,生成的hash签名(字符串,序列)也越相似
(对于两个document,在Min-Hashing方法中,它们hash值相等的概率等于它们降维前的Jaccard相似度。可以从杰卡德的定义式子看出,杰卡德的定义式恰好就是第一次“遇到”1的概率。)
对不同样本的哈希签名求杰卡德相似度来替代直接对向量求杰卡德相似度
本质上就是随机抽样比较相似度
min-hash等同于降维
可操作min-hash
我们原始目的:随机打乱之后,找出第一个非零行的索引行号
原始min-hash每次都要重新排序这样实在太耗时间空间了,所以我们采用了另一种办法:运动是相对的,我们不打散行,我们打散行号23333 。
具体怎么操作呢?打散行号之后,我们依然从原序号的顺序开始遍历,我们对行号进行hash不断的替换最小行号达到我们原始的目的。
比如:对于一个向量,进行一次打散,使用hash函数$hash(x)$计算行号,将原顺序行号映射到新的hash空间
顺序遍历,顺序1行为0:pass
顺序第2行为1:计算$hash(1)=5$,那么此时最小行号$hash_{min}=5$
顺序第3行为0:pass
顺序第4行为1:计算$hash(1)=3\quad,3<当前最小行号hash_{min}=5$,于是替换最小行号!那么此时最小行号替换为$hash_{min}=3$
顺序第5行为1:计算$hash(1)=8\quad,8>当前最小行号hash_{min}=3$,不替换,依然不变:$hash_{min}=3$
以此类推,最后遍历完这个向量之后,就得到了最小行号,也即打乱行号之后出现第一个1的行号
第二次打散,就换一个$hash$函数进行打散
以此类推,打散了$n$次,就设置了$n$个不同的哈希函数来计算打散的行号,每个原向量就得到了$n$次min-hash结果,就得到了一个$n$维的新向量
一次随机打散行,其实就是一次对行号的散列,其实就是对行号计算一次哈希值。我们要打散多少次,实际上就是有多少个作用于行号的不同的哈希函数,也就是经过min-hash处理后向量的长度。
Locality Sensitive Hashing
为什么要用LSH
min-hash只是降低了每一个向量的维度,并没有减少比较次数,当向量数量很大的时候,依然非常耗时间
假设原向量(文本)有$m$个,则时间复杂度没变$O(m^2)\to O(m^2)$
于是有了局部敏感哈希算法,LSH
原理
LSH是一种基于min-hash的加速索引算法,建立一种新的索引
其基于思想:如果将两个向量以相同方法划分若干段,如果这两个向量相似,那么他们被划分出的对应若干段中存在某段完全相同(=段中每维完全相同=hash值相同=被分到同一个hash分桶)的概率也很高;同理不相似的向量,其哈希值只有很小的概率是相同的。那么我们就可以只比较可能相似的样本,不太可能相似的样本就不比较,这样就减小了比较次数
LSH具体地算法是:
①将每个原向量(一个数据点)通过min-hash得到的hash签名(下称:向量),划分为$b$段,每段有$r$行
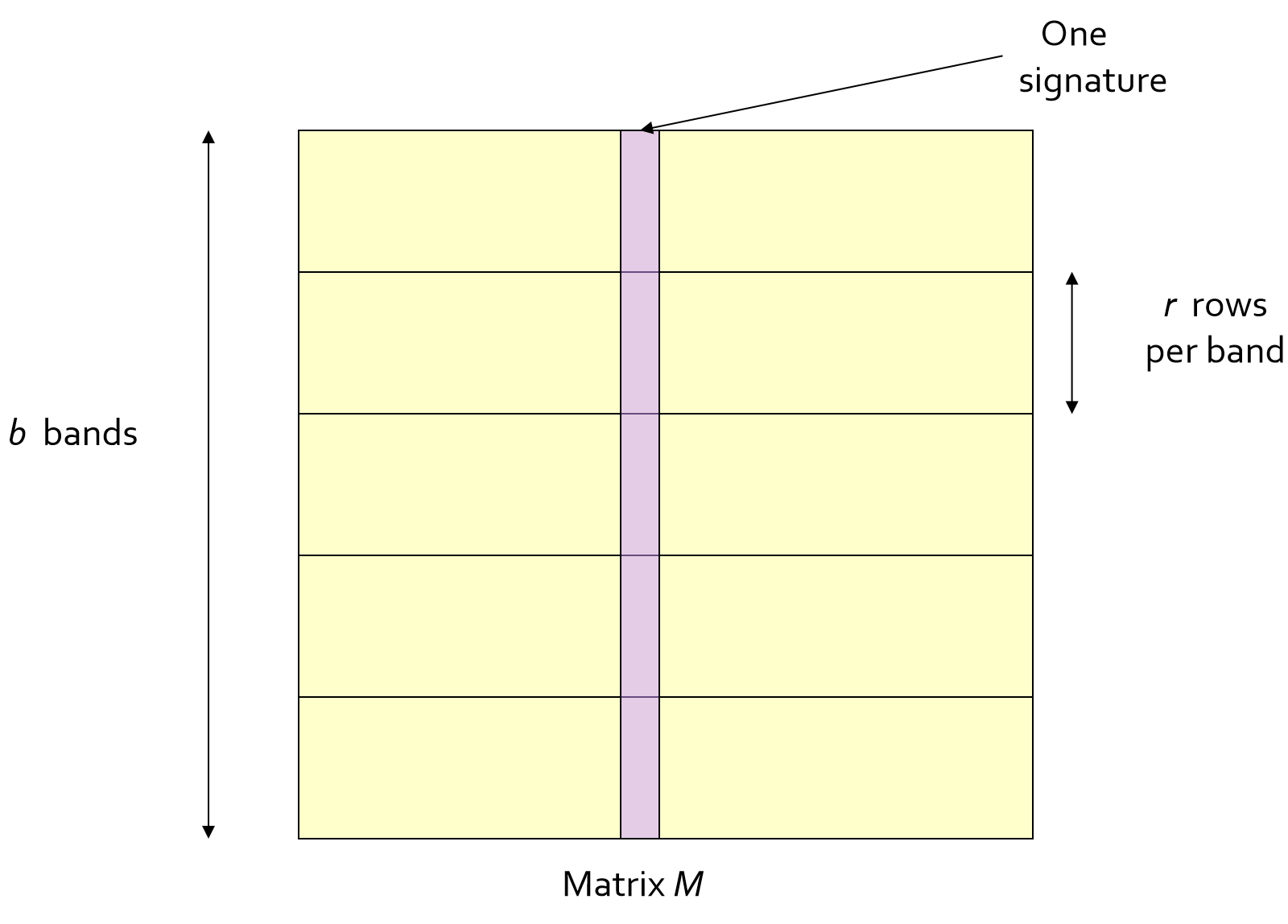
如图矩阵$M$,每一列代表一个向量,每一行就是一个向量的维度,$r$个维度(行)组成一个段
②对每行的每个段进行hash映射,不同样本(竖)的该段截取的部分段向量(横)如果相同就会被映射到一个桶中。
(每一行可以使用相同的hash函数,但是每一行各段都是被映射到不同的数组的,数组里的每一个元素就是桶)
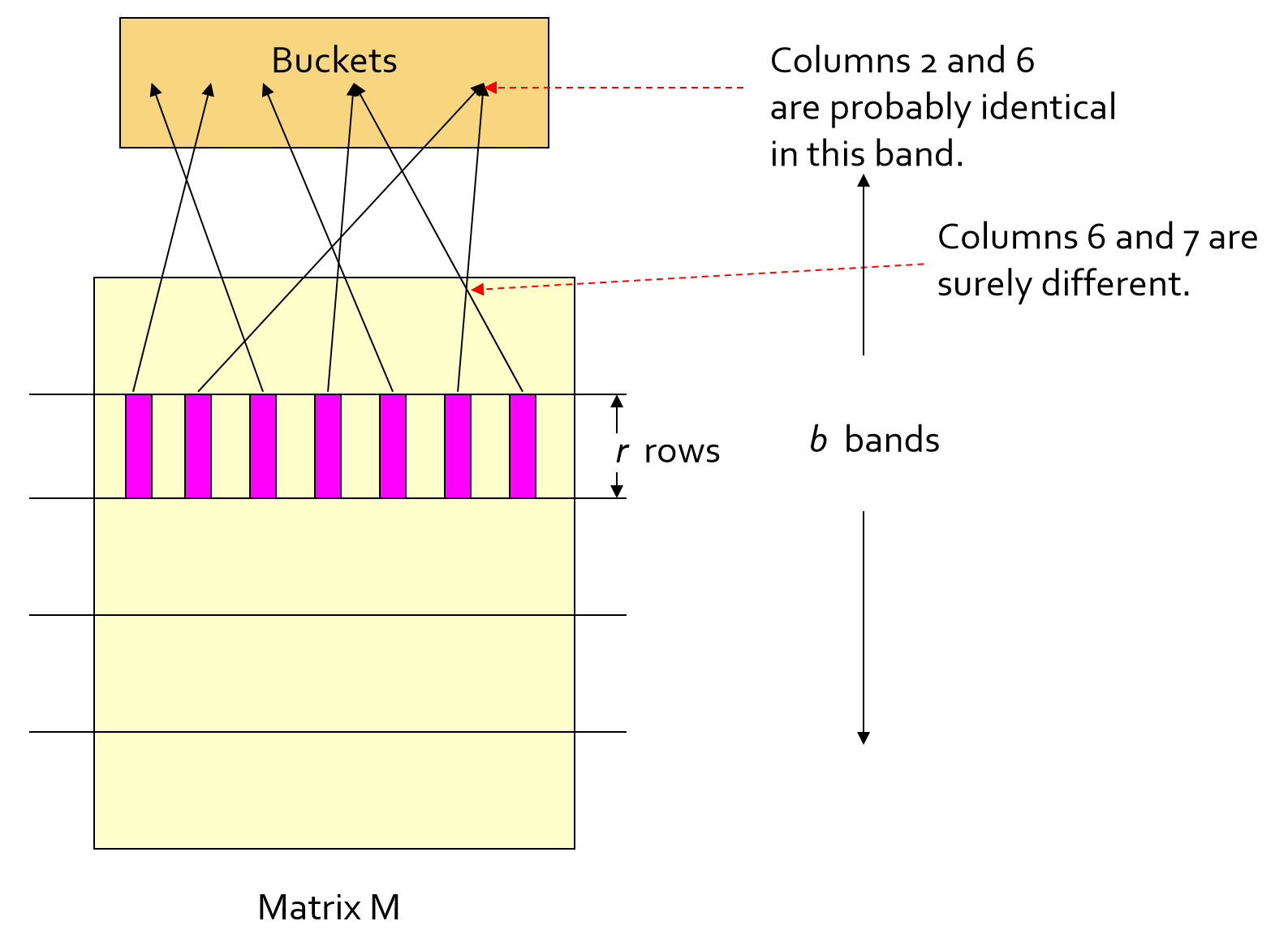
③我们应用一个假设:我们称每个段的每一个桶内,即不同样本中至少有一个段相同(=hash值相同=被分到同一个hash分桶)的样本为候选相似样本。通过下面的证明可得,我们只对候选相似样本进行比较,便可以以极大概率找到所有可能相似样本。
假设的证明:我们假设AB 两个样本相似度为$a$,那么将A、B分成$b$段,每段$r$行。那么A、B在某段里,每一行的相似概率就为$a^r$, 那么A、B在该段每一行都不相似的概率就为$1-a^r$,A、B所有段都不同的概率为$(1-a^r)^b$,A、B至少有一个段相似的概率为$1-(1-a^r)^b$,最后这个式子就是两个样本可能相似的概率
$a∽1-(1-a^r)^b$画成图像是S形的,它表征了相似度$a$作为自变量与A、B至少有一个段相同的概率的关系,如下:
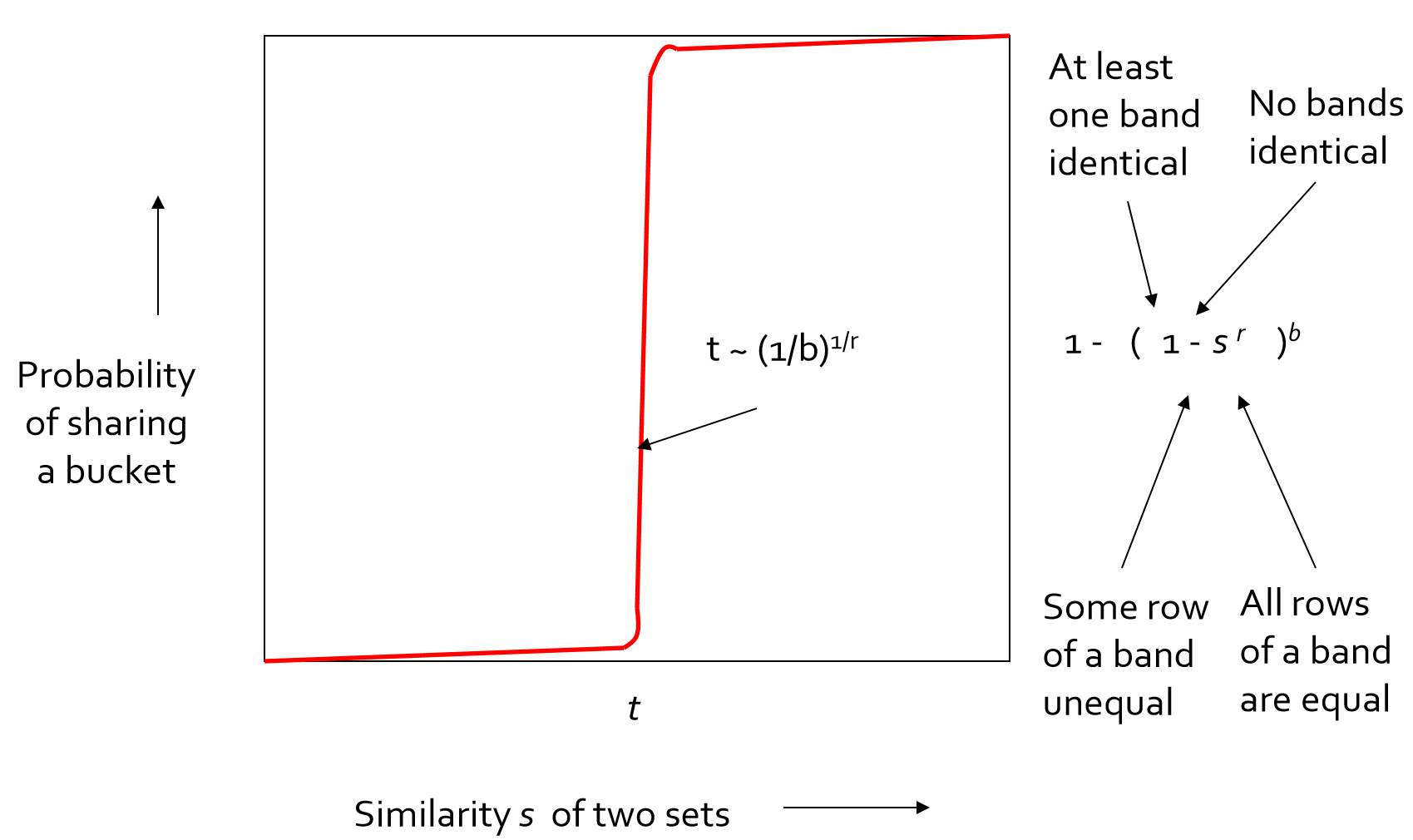
(此图中$s$即相似度$a$,最陡的地方为$a=(1/b)^{1/r}$;$t$为相似判定阈值,设定大于该阈值则认为两个样本相似)
从$a∽1-(1-a^r)^b$图中可以看到,当两个样本的相似度$a$超过一定阈值的时候,$1-(1-a^r)^b$也就是A、B至少有一段相同的概率骤升,A,B任何一段都不相同的概率骤降,所以我们就排除出了不太可能相似的样本,而获得了可能相似的样本。也就是说,只要我们将至少存在一段相同的样本选做候选点,就可以以极大概率捕获相似样本。
于是我们就可以只比较可能相似的样本,也就是有段落在同一个桶内的样本了
理解名字:“局部敏感哈希”,这个局部就是指的这个分段。如果两个向量局部相同,根据上面证明,那么两个向量可能相似的概率就远远大于不可能相似的概率。
总结:Min-Hash降维,LSH减少查找范围;如何减少查找范围?通过找存在相同band的样本来找可能相似的样本。
(注意桶应该设置大一点,避免hash碰撞)
参数调节
参数:分段数$b$,相似判定阈值$t$;
可以看出,分段数越多,返回的相似候选点越多,漏报率越低(当分段数=minhash后向量长度,那就退化成直接比较了)
我们可以通过调节这个$a∽1-(1-a^r)^b$曲线来满足我们的实际需求
如果我们想要尽量少漏掉相似样本:那么就应该调节分段数$b$和相似判定阈值$t$,尽量让我们的相似度判断阈值尽量在S曲线的右上角,这样一来候选点相似的概率大于该相似度阈值的概率就尽量大了
如果我们想要查询速度快:我们就应该调节分段数$b$和相似判定阈值$t$,尽量让S曲线中间的爬升坡度更陡峭,这样一来相似度没那么高的向量就很难成为候选点
于是就可以根据我们实际任务的需求,调节曲线的形状和阈值的位置
这里的参数调节分析可以见LSH举例子,写得很好
Tools
sklearn.neighbors中实现了LSHForest(局部敏感随机投影森林)也可以直接用lshash包:
对于py2,使用
lshash包;对于py3,使用lshash3包但注意py3是默认没有
future库的,需要自己安装其官方文档:https://pypi.org/project/lshash3/
用汉明距离代替杰卡德距离计算
实现lsh最好的开源工具是
falconn这个库基于论文 Practical and Optimal LSH for Angular Distance
是对原始LSH的极致优化
这是falconn py的说明文档https://falconn-lib.org/pdoc/falconn/
注:图片来源斯坦福LSH课件


