

Principal Component Analysis, PCA
PCA的核心思想是①先对数据规范化,均值为0,方差为1。②再对原基下的数据进行正交基变换,将由线性相关变量表示的数据变成由线性无关变量表示的数据。变换过程遵循表示信息最大的原则,即选择使得变换后数据方差最大的变量(主成分)作为新变量,也就是新维度下的数据越分散越好。
这样的变换过程可以理解为转换观察数据的角度,揭示出数据内在的结构。
把数据依信息最大(方差最大)顺序由少量主成分表示即是对数据降维,其就是想用较少的没有相关性的变量来获取尽可能多的原始数据信息。
在数据总体上进行的主成分分析称为总体主成分分析,在有限样本上进行的主成分分析称为样本主成分分析。
正交基变换
见前文矩阵计算与矩阵分解-基本计算-12-基变换
[理解基变换的几何意义:向量在新基组上的投影]
$X$为原矩阵下的向量(坐标),$X=(\mathbb x_1,\mathbb x_2,\cdots,\mathbb x_n)$,有$n$个原基下的$\mathbb x$向量
$A$为正交基矩阵 $A=(a_1,a_2,\cdots,a_m)$,其中的每个向量就是一个新的基,新基是相互正交的
$\mathbb x_i和a_j$都是$m$维列向量,$\mathbb x_i$代表原基下的一个向量/坐标,那么
即为基变换,新基下的向量为$Y=(\mathbb y_1,\mathbb y_2,\cdots,\mathbb y_n)$
$\mathbb y_i$也是$m$维列向量,代表经过基矩阵$A$变换后新基下的坐标
也可以半展开写成:(这里转置易错,外面那层转置只是转置了外层的列,每列内部还要进行转置)
在该基变换中,每一个旧基下的向量$\mathbb x_i$都左乘了基矩阵$A$ ,也就是:
如果只有一个向量$x$做基变换,那便是:
展开列向量$\mathbb y$中的每一个维度表示:即$y_i=a_i^T\mathbb x=a_1x_1+a_2x_2+\cdots+a_mx_m$
这样变换的原理:
可以看出变换得到的新基下的变量的每个维度都由基矩阵的一个列向量也就是一个基与原基下的变量内积得到,新向量的一个维度为基矩阵的一个基与原基变量的内积,就是上面这个式子
而内积的几何意义是:向量$A与B$的内积实质上就是$A$到$B$的投影长度乘以$B$的模,如果$B$为单位向量,那么$A与B$的内积就是$A$到$B$上的投影,也就是向量$\mathbb x$在新基组$(a_1,a_2,\cdots,a_m)$下的投影,也就得到了新基下的坐标/向量表示:$\mathbb y$。原基下的向量$\mathbb x$被投影到了每一个新基($a_i$)上,组成了新基下的向量表示(坐标):$\mathbb y$。
用图表示关系就是
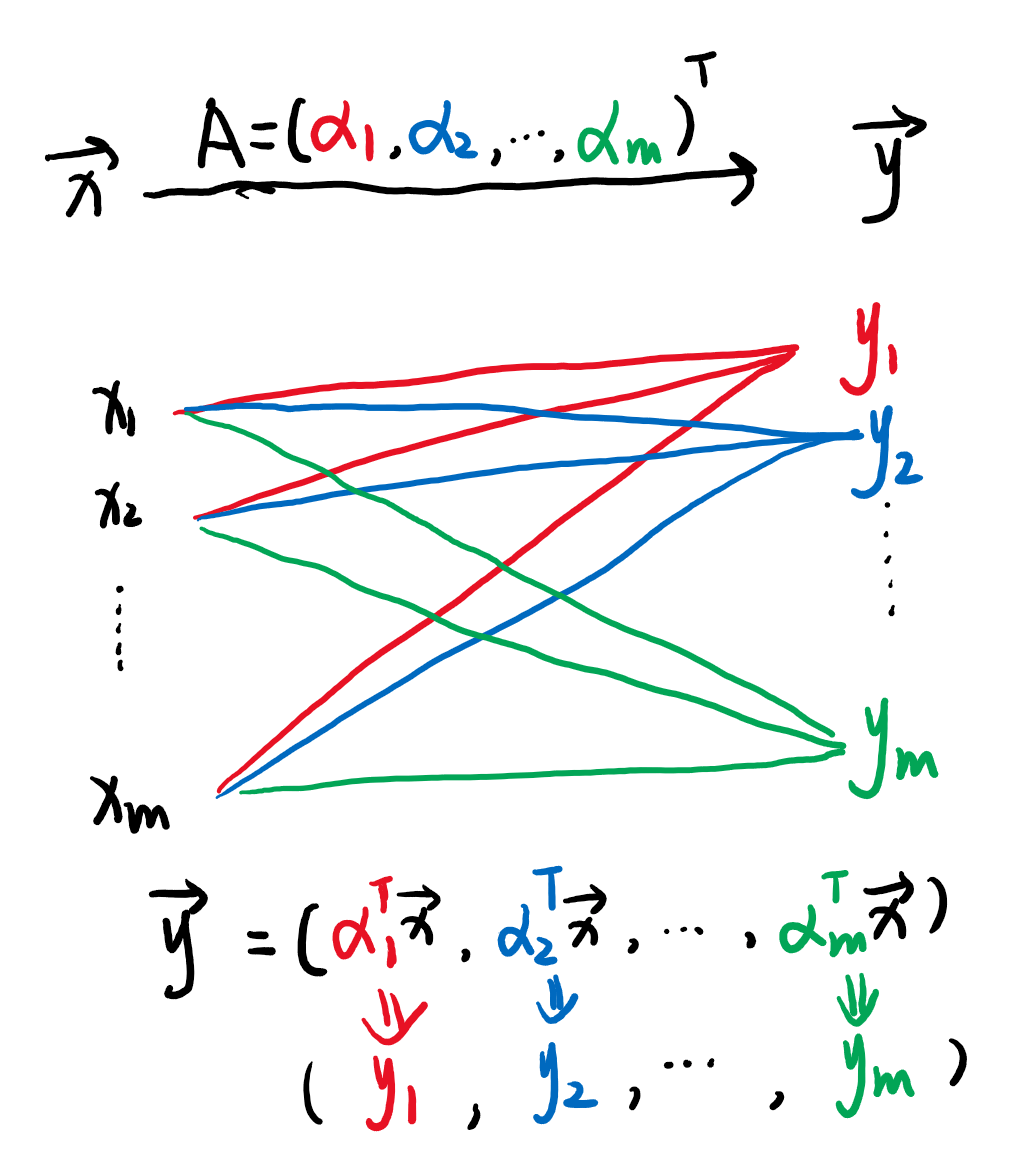
各个颜色的变换就是内积,就是一次原基下的向量表示到某一个新基的投影过程
举例,对于一般的二维笛卡尔直角坐标系中,其基为$a_1=(0,1)^T,a_2=(1,0)^T$,其正交基矩阵就是
$A=\begin{bmatrix}a_1,a_2\end{bmatrix}=\begin{bmatrix} 0&1\\1&0 \\ \end{bmatrix}$,对于本来就在笛卡尔坐标系下的向量$\mathbb x$,自然$\mathbb x=A^T\mathbb x$,新基和原基没变,那向量表示(坐标)自然也没变
总体主成分分析
定义
[PCA的核心]:对原来的基下的数据向量$\mathbb x$做正交基变换($\mathbb y=A^T\mathbb x$),求出使得变换后$\mathbb y$的方差和[最大]的正交基矩阵$A$,得到新基下的新向量$\mathbb y$,此新向量即主成分,此向量各个维度依方差大小排序为第$i$主成分。
为什么要方差最大?因为某新基下数据方差越大($var(y_i)$),保留信息就越多,该新基就越重要,就是$\mathbb x$越主要的成分。主成分$\mathbb y$就是这个方差最大化问题的最优解。
[具体地]——
一个数据$\mathbb x$由一个向量也即一个坐标表示
$\mathbb x$是$m$维向量(即特征是$m$维),$\mathbb x=(x_1,x_2,\cdots,x_m)^T$,其均值(向量)为$\mu=\mathbb E(x)$$=(\mu_1,\mu_2,\cdots,\mu_m)^T$
总体PCA是什么以及和样本PCA的关系:在总体PCA中,已知向量(随机变量)$\mathbb x$的分布,这时就可以直接求出其均值$\mu$,这种情况对$\mathbb x$求主成分就是总体PCA,是直接给出了$\mathbb x$的分布函数,然后求$\mathbb x$的主成分。而在实际问题中一般不会已知分布函数,而是已知一个样本集,我们从样本集中求出均值,对实际样本数据求主成分,这种就是样本PCA。可以看出对于给定样本集求出的均值就是一个对样本集的总体分布参数的一个估计,我们用观测的样本集的均值去估计了没有直接给出的分布参数。
$\mathbb x$代表了一个(原基变量下的)随机变量(向量/数据样本);下面我们要经过正交基变换(左乘基变换矩阵$A$)得到的$\mathbb y$是一个(新基变量下的)随机变量(数据向量)。
根据上面的思想,我们要将一个随机变量$\mathbb x$其经过一个线性变换(基变换)$A$,$\mathbb x\to \mathbb y$:
[几何理解]:$A$就是基矩阵,其中的向量就是正交基。经过变换求得的$y_i$是个数,是原向量到新基$\alpha_i$的投影(内积),$\mathbb x$的每个维度在所有新基$(\alpha_1,\alpha_2,\cdots,\alpha_m)$上的投影$(y_1,y_2,\cdots,y_m)$构成了新基下的向量$\mathbb y$
总结下来就是如下——
[满足以下条件](下称—定义条件):
系数向量$\alpha_i^T$是单位向量,即$\alpha_i^T\alpha_i=1,\quad i=1,2,\cdots,m$
新向量$\mathbb y$的各个维度$y_i$与$y_j$互不相关,即$cov(y_i,y_j)=0\quad(i≠j)$
$y_i$是①与前面求出来的新向量$\mathbb y$的各个维度$y_1,y_2,\cdots,y_{i-1}\quad(i=1,2,\cdots,m)$都不相关(也就是要确保是正交变换)
②且是原向量$\mathbb x$的所有线性变换(基变换)中方差最大的
得到的新向量$\mathbb y$的各个维度$y_i$即是$\mathbb x$的主成分,这时分别称$y_1,y_2,\cdots,y_m$为$\mathbb x$的第一主成分,第二主成分,$\cdots$,第$m$主成分,组成的$\mathbb y$就是总体主成分。
[理解]:线性变换得到的$\mathbb y$有很多,只有满足以上条件得到的$\mathbb y$才是主成分(我们想要的一种最能代表原向量结构的一种线性变换)。只有最优解叫主成分,其它线性变换都不叫主成分!
[为了避免混淆写一句]:
一个数据样本$\mathbb x$经$A$基变换后求得一个$\mathbb y$,$\mathbb y$中的每个维$y_i$是主成分,即$\mathbb x$在新基下各个维度的投影;一个数据样本有$m$维,所以有$m$个主成分
一组数据样本$X=(\mathbb x_1,\mathbb x_2,\cdots,\mathbb x_n)$经$A$基变换后求得一组$Y=(\mathbb y_1,\mathbb y_2,\cdots,\mathbb y_n)$,每个样本都被变换到新基下,每个样本都有$m$个主成分,也即$\mathbb x$在新基下各个维度的投影(这就是实际情况,样本PCA,考虑多个数据样本,这样就实际可以求出样本的均值了)
根据定义中的2,3就可以得出PCA的推导方法,实际上就是个约束最优化问题,见下
性质
注意定义$\alpha,\mathbb x$都是列向量,分别代表一个向量和基变换矩阵里的一个基
$\mathbb x=(x_1,x_2,\cdots,x_m)^T,\alpha_i=(\alpha_{1i},\alpha_{2i}\cdots,\alpha_{mi})^T,\quad i=1,2,\cdots,m$
矩阵计算——协方差矩阵
对于$n$个上述向量$\mathbb x$的向量组,$X=(\mathbb x_1,\mathbb x_2,\cdots,\mathbb x_n)$
定义协方差矩阵为$cov(X,X)=\begin{bmatrix}cov(\mathbb x_1,\mathbb x_1)&cov(\mathbb x_1,\mathbb x_2)&\cdots&cov(\mathbb x_1,\mathbb x_n)\\cov(\mathbb x_2,\mathbb x_1)&cov(\mathbb x_2,\mathbb x_2)&\cdots&cov(\mathbb x_2,\mathbb x_n) \\ \vdots&\vdots&\ddots&\vdots\\cov(\mathbb x_n,\mathbb x_1)&cov(\mathbb x_n,\mathbb x_2)&\cdots&cov(\mathbb x_n,\mathbb x_n) \\ \end{bmatrix}$
其中每个元素为:$cov(\mathbb x_i,\mathbb x_j)=\mathbb E[(\mathbb x_i-\mathbb E(\mathbb x_i))(\mathbb x_j-\mathbb E(\mathbb x_j))]$,于是这个矩阵可以表示为:
$cov(X,X)=\mathbb E[(X-\mathbb E(X))(X-\mathbb E(X))^T]=\frac{1}{n-1}(X-\mu)(X-\mu)^T$
$=\frac{1}{n-1}\begin{bmatrix} \mathbb x_1-\mu_1 &\mathbb x_2-\mu_2 & \cdots &\mathbb x_n-\mu_n\\ \end{bmatrix}\begin{bmatrix} \mathbb (x_1-\mu_1)^T\\ \mathbb (x_2-\mu_2)^T\\ \vdots\\ \mathbb (x_n-\mu_n)^T\\ \end{bmatrix}$
(分母为$n-1$:因为随机变量的数学期望未知,以样本均值代替,自由度减一)
以下设期望$\mu=0$,则对协方差矩阵中的每一位有:$cov(\mathbb x_i,\mathbb x_j)=\mathbb E[\mathbb x_i·\mathbb x_j]=\frac{1}{n-1}\mathbb x\mathbb x^T$
$=\frac{1}{n-1}\begin{bmatrix} \mathbb x_1 &\mathbb x_2 & \cdots &\mathbb x_n\\ \end{bmatrix}\begin{bmatrix} \mathbb x_1^T\\ \mathbb x_2^T\\ \vdots\\ \mathbb x_n^T\\ \end{bmatrix}=\frac{1}{n-1}(\mathbb x_1\mathbb x_1^T+\mathbb x_2\mathbb x_2^T+\cdots+\mathbb x_n\mathbb x_n^T)$
注意$\mathbb x_i\mathbb x_j^T$求得的是一个矩阵,左行右列:$\mathbb x_{m×1}×\mathbb x_{m×1}^T=\mathbb x_{m×1}×\mathbb x_{1×m}=[\mathbb x\mathbb x^T]_{m×m}$
那么最终相加和之后的$XX^T$也是一个$m×m$的矩阵,每一位都是$x_i$和$x_j$的协方差的在所有样本向量上的期望
设$X_{m×n}$的协方差矩阵为$S_{m×m}$,则其中每一位为:
【最后求出来的协方差为$m×m$形状的矩阵$S_{m×m}$表达了什么意义?这个矩阵的每一位(见上式)就是随机变量$\mathbb x$中的第$i$维$x_i$和第$j$维$x_j$在整个样本集上的协方差的期望】
而对于总体PCA,就相当于$n=1,X={\mathbb x}$,一个样本的期望(即平均)就是其本身,$s_{ij}=x_ix_j$
(后半部分都设了均值$\mu$为0,不为0的表达式就多一项,每个维度计算的时候需要减去该维度在所有样本向量该维度上的均值,懒得写了)
对于只有一个向量$\mathbb x$,就就相当于$n=1,X=[\mathbb x]$。协方差矩阵:$cov(\mathbb x,\mathbb x)=\frac{1}{1}×(\mathbb x-\mu)(\mathbb x-\mu)^T$.
(在总体PCA中我们只需要求一个$\mathbb x$的协方差矩阵,而在样本PCA中,考虑样本集,就是要求$n$个样本组成的向量组的协方差矩阵了)
若对$\mathbb x$进行规范化(见后)使得$\mathbb E(\mathbb x)=0$$,var(\mathbb x)=1$,则
这里只是求了一个向量$\mathbb x$的协方差矩阵;对于下面的样本PCA,要求在样本集$X_{m×n}$上的协方差矩阵(见样本PCA)
为什么需要求$cov(\mathbb x,\mathbb x)$,因为后面在求$var(y_i)$和$cov(y_i,y_j)$的时候都导出了$cov(\mathbb x,\mathbb x)$表示的表达式,而且在定理一中得出了$\mathbb x$的协方差矩阵和主成分之间的一个重要关系。(对角化的)协方差矩阵即包含了方差最大的优化目标,又包含了两两维度协方差为0 的目标
a)对于$\mathbb x=(x_1,x_2,\cdots,x_m)^T$,为$m$维变量非正交,$cov(\mathbb x,\mathbb x)=\begin{bmatrix}{var(x_1)}&{\cdots}&{cov(x_1,x_m)}\\{\vdots}&{\ddots}&{\vdots}\\{cov(x_m,x_1)}&{\cdots}&{var(x_m)}\\ \end{bmatrix}$
b)对于$\mathbb y=(y_1,y_2,\cdots,y_m)^T$,为$m$维变量正交,$cov(\mathbb y,\mathbb y)=\begin{bmatrix}{var(y_1)}&{0}&{0}\\{0}&{\ddots}&{0}\\{0}&{0}&{var(y_m)}\\ \end{bmatrix}$
因为对于正交的$y_i,y_j,有cov(y_i,y_j)=0$
矩阵计算——重要结论
对于$y_i=\alpha_i^T \mathbb x,\quad \alpha_i^T=(\alpha_{1i},\alpha_{2i}\cdots,\alpha_{mi}),\quad i=1,2,\cdots,m$
$\mathbb E(y_i)=\mathbb E(\alpha_i^T\mathbb x)=\alpha_i^T \mathbb E(\mathbb x)$
若规范化,$\mathbb E(y_i)=0$
$var(y_i)=var(\alpha_i^T\mathbb x)=\alpha_i^T cov(\mathbb x,\mathbb x)\alpha_i$
推导:$var(\alpha_i^T\mathbb x)=(\alpha_{i}^T\mathbb x-\mathbb E(\alpha_{i}^T\mathbb x))^2=(\alpha_{i}^T\mathbb x)^2$,这里求方差略去分母。
$\alpha_{i}^T\mathbb x$为向量内积,为一个数,一个数的转置还是本身,那么原式$=(\alpha_{i}^T\mathbb x)(\alpha_{i}^T\mathbb x)^T=\alpha_{i}^T\mathbb x\mathbb x^T\alpha_{i}$,而$cov(\mathbb x,\mathbb x)=\mathbb x\mathbb x^T$,则$var(\alpha_i^T\mathbb x)=\alpha_i^T cov(\mathbb x,\mathbb x)\alpha_i$
$cov(y_i,y_j)=cov(\alpha_i^T\mathbb x,\alpha_j^T\mathbb x)=\alpha_i^T cov(\mathbb x,\mathbb x)\alpha_j$
推导:同上理
[注]:
显然2,3中的方差和协方差求出来的都是一个数,因为$cov(\mathbb x,\mathbb x)=\frac{1}{m-1}\mathbb x\mathbb x^T$的形状为$m×m$,$\alpha_i$的形状为$m×1$,则$[1×m][m×m][m×1]=1×1=constant$
规范化
$x_i^o$就是$\mathbb x_i$的规范化随机变量。(性质略)
对各个维度规范化后$\mathbb x^o=(x_1^o,x_2^o,\cdots,x_m^o)^T$。于是$\mathbb x^o$的$\mathbb E(\mathbb x^o)=0$$,var(\mathbb x^o)=\sigma=1$
根据定义推导主成分应满足的条件
定理一:总体主成分$\mathbb y$与$\mathbb x$的协方差矩阵$\Sigma$(及其特征值$\lambda$和特征向量$\alpha$)的关系
设$\mathbb x$是$m$维随机变量,$\Sigma$是$\mathbb x$的协方差矩阵($\Sigma=cov(x,x)$),$\Sigma$的特征值分别是$\lambda_1≥\lambda_2≥\cdots≥\lambda_m≥0$。特征值对应的单位特征向量分别是$\alpha_1,\alpha_2,\cdots,\alpha_m$,则$\mathbb x$的第$k$主成分表达式是:
[结论]则其方差为:(注意理解此式子)
这个定理的意义是:
①主成分$y_k$的方差=$\mathbb x$的协方差矩阵对应的特征值$\lambda_k$
②主成分$y_k$的正交变换$\alpha_k$(基)对应协方差矩阵的特征向量
(注意回到定义-理解去理解一下主成分)
知道了主成分$\mathbb y$的方差和原向量$\mathbb x$的协方差矩阵$\Sigma$的特征值$\lambda_i$和特征向量$\alpha_i$的等价关系,即在什么条件下是原问题的最优解(主成分),这样我们就能求解出主成分了。下面的推论给出了充分必要条件。
如果我们想要降维,这就引出了定理二
推导过程(简略)——方差最大化的约束最优化问题:
这个定理就是我们在推导求解PCA的过程中得到的,根据定义,求解PCA实质上是个方差最大化的约束最优化问题。
①根据上节对PCA的定义,可以将求PCA(先求第一主成分$y_1$)转化为一个约束最优化问题:
注意!发现这里求出来的是一个协方差矩阵$\Sigma$的特征向量方程的形式!可以看成$\lambda$是特征值,$\alpha_1$是特征值对应的特征向量
也就是说:这个特征向量方程的解,也就是这个约束最优化问题的解
假定$\lambda_1$是$\Sigma$的最大特征值,其对应向量为$\alpha_1$,于是:
所以$\alpha_1^T\mathbb x$构成了第一主成分$y_1$,其方差等于$\mathbb x$的协方差矩阵$\Sigma$的最大特征值:
②下面继续求第二主成分,问题转化为下一个约束最优化问题
由定义条件3-①可知,$y_2$要与$y_1$线性无关,也即协方差为0:那么写出求第二PCA的约束最优化问题:$cov(y_1,y_2)=0$
与①一样,用拉格朗日乘子法解这个最优化问题:
左乘$\alpha_1^T$有:$2\alpha_1^T\Sigma\alpha_2-2\alpha_1^T\lambda\alpha_2-\phi\alpha_1^T\alpha_1=0$,又由于$\alpha_1^T \Sigma\alpha_2=0$,$\alpha_1^T \lambda\alpha_2$为前者的一个分量,也等于0,于是可以得到:
这又是一个和①形式一样的特征向量方程,于是同样取第二大的特征值$\lambda_2$,对应特征向量$\alpha_2$
所以$\alpha_2^Tx$构成了第一主成分$y_2$,其方差等于$x$的协方差矩阵$\Sigma$的第二大特征值:
③对于后面的第$k$主成分都同理,有:
于是得到上面的定理
[核心结论]推论:主成分的充要条件
推论:$m$维随机变量$\mathbb y=(y_1,y_2,\cdots,y_m)^T$的分量依次是$\mathbb x$的第一主成分到第$m$主成分的充要条件是:(由定理一推导过程可得)
条件一:$\mathbb y=A^T\mathbb x$,$A$为正交矩阵
条件二:$\mathbb y$的协方差矩阵$cov(\mathbb y,\mathbb y)=\frac{1}{n-1}\mathbb y \mathbb y^T$为对角矩阵:
$\lambda_k$是$\mathbb x$的协方差矩阵$\Sigma$的第$k$个特征值,$\alpha_k$是对应的单位特征向量,$k=1,2,\cdots,m$
(这里使用$\mathbb y$的协方差是为了方便表示一个由所有$y_i$的方差所表示的对角矩阵,见矩阵计算-协方差矩阵-b))
这里据前面的定理一可以得到:(定理一的右半部分$\alpha_k^T\Sigma\alpha_k=\lambda_k$换成矩阵表示)
【核心总结】也就是说:通过协方差矩阵的【正交】【对角】分解(满足1,2条件)即可获得主成分(最优解)。具体关系是:$\mathbb x$的协方差矩阵$\Sigma$的对角矩阵的特征值构成主成分$\mathbb y$的方差,协方差矩阵的特征向量构成基矩阵$A$。
根据这个推论(充要条件),问题就被转化为求矩阵正交对角化了。那数学上就可以用矩阵分解来解决,矩阵分解的办法就很多了。得到PCA的两种求解方法,见后面
由定理一和推论得到性质总结
总体主成分$\mathbb y$的协方差矩阵是对角矩阵
(此性质即为前面得出的核心结论)总体主成分$\mathbb y$的方差之和等于随机变量$\mathbb x$的方差之和,即
其中$\sigma_{ii}$是随机变量$x_i$的方差,即协方差矩阵$\Sigma$的对角元素
第$k$个主成分$y_k$与变量$x_i$的相关系数$\rho(y_k,x_i)$称为因子负荷量,表示第$k$个主成分与变量$x_i$的相关关系
由此可以得到一些关系,$\sum_{i=1}^m\sigma_{ii}\rho^2(y_k,x_i)=\lambda_k\quad,\quad \sum_{k=1}^m\rho^2(y_k,x_i)=1$
具体略
定理二:选择方法——选取$k<m$个主成分下如何选择主成分是最优选择
由定理一将问题转化为求解最大化协方差矩阵的特征值之和,定理二就是为了解决这个问题——怎样才能使得协方差矩阵的特征值之和最大
注意这里容易误解:这个定理是证明了选取前$k$个($y_1,y_2,\cdots,y_k$)主成分这种选择方法是最优选择(方差最大化),其他选择还有比如:选择第1,4,5,6个主成分,选择第2,8,9,10个主成分,这些都不是最优选择
之所以要取前$k$个主成分是为了降维
定理二:对任意正整数$q,1≤q≤m$,考虑正交变换
其中$y$是$q$维变量,$B^T$是$q×m$矩阵,$\mathbb x$依然是$m$维原向量,令$y$的协方差矩阵为
则$\Sigma_y$的迹$tr(\Sigma_y)$(这个迹就是对角线和也就是方差和)在$B=A_q$时取最大值,其中矩阵$A_q$由正交矩阵$A$的前$q$列组成
这个定理证明了如果要降维($k<m$),选前$k$个主成分是最优选择
证略
$k$的取值:选择几个主成分——由累计方差贡献率决定
这里才是分析应该选取的主成分变量的数量$k$
方差贡献率定义:第$k$主成分$y_k$的方差贡献率定义为$y_k$的方差与所有方差之和的比,记作$\eta_k$
$k$个主成分$y_1,y_2,\cdots,y_k$的累计方差贡献率定义为$k$个方差之和与所有方差之和的比
通常取$k$使得累计方差贡献率达到规定的百分比以上,累计方差贡献率反映了主成分保留信息的比例,由此来决定选择几个主成分($k$的值选取)
对原向量的一个维度$x_i$保留信息的比例为
其实就是计算$x_i$与所有新维度$y_1,y_2,\cdots,y_k$的相关系数之和,这就算出来$x_i$在变换后保留信息的比例
后记
- 期望,方差,协方差运算可以看这里:http://www.360doc.com/content/13/1124/03/9482_331690142.shtml
- 协方差矩阵可以参考:https://blog.csdn.net/xueluowutong/article/details/85334256
- PCA通俗讲解:https://zhuanlan.zhihu.com/p/21580949
- 方差$\sigma$。。。


